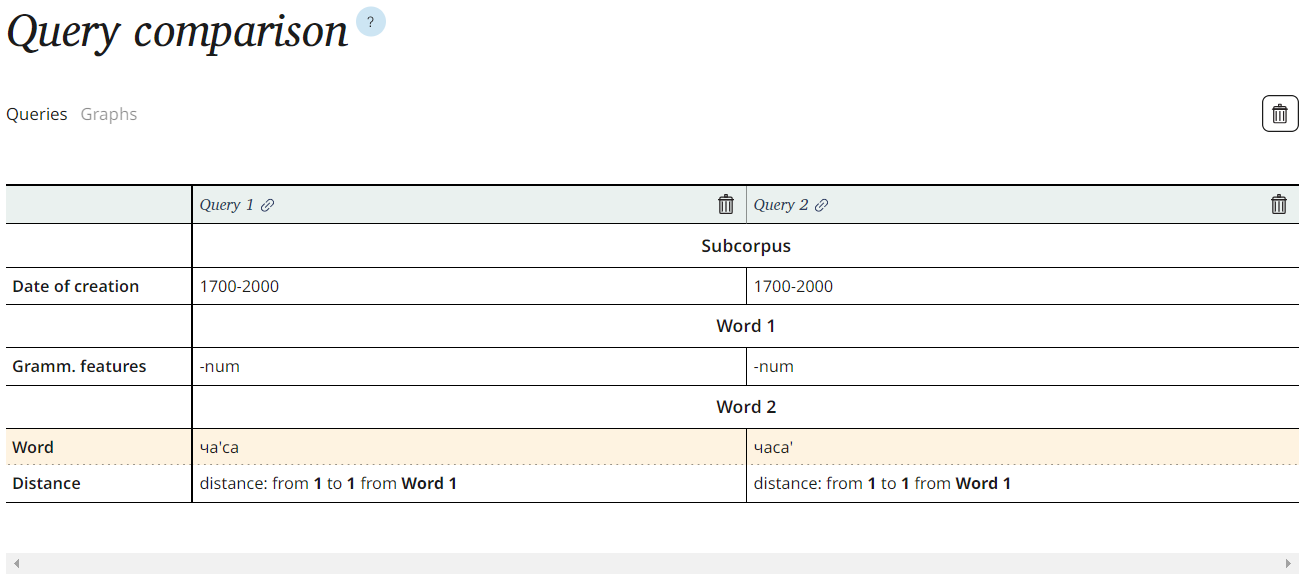
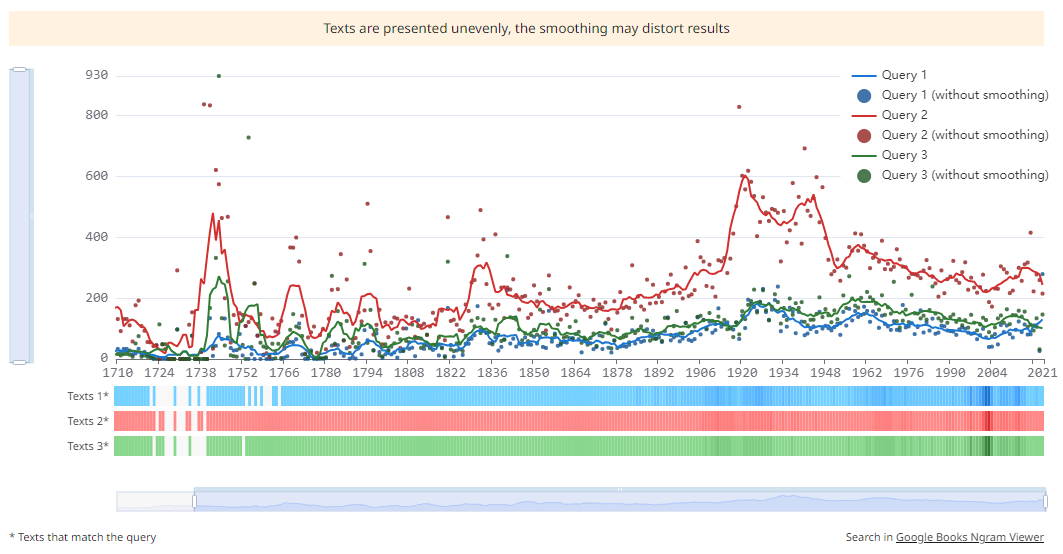
For research, it is often necessary to analyze the results of several search queries simultaneously. Until now, most users have been comparing results independently by copying or uploading search results into Excel. For the main corpus, there has been an option to compare the results of the exact form search.
Since October 2023, the advanced option to compare results of multiple queries is available in the Corpus:
- you can compare search queries of different types, for example, the results of two lemma and tags searches, or an exact search and a lemma and tags search
- collocation search or bilingual search cannot be included in the comparison, as these are fundamentally different types of search results.
- all comparisons are made within the same corpus, but different subcorpora can be specified in different queries.
- we ask you to sign in when working with comparisons, in order to be able to store a large number of query parameters and return to the comparison.
The comparison option is available works in all corpora in the new interface, wherever the graph is available.