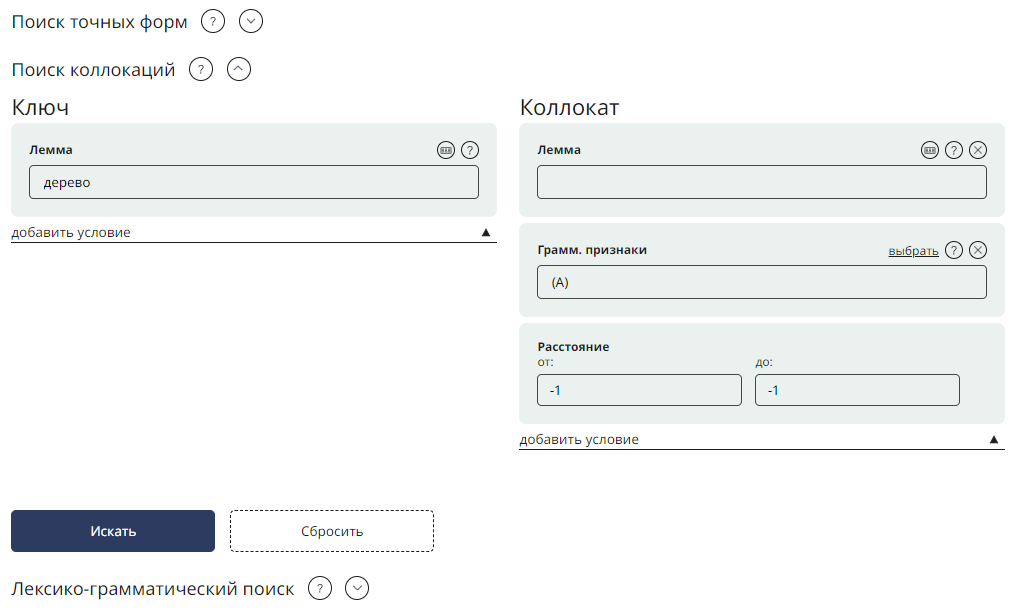
Коллокациями называют слова, которые часто встречаются вместе.
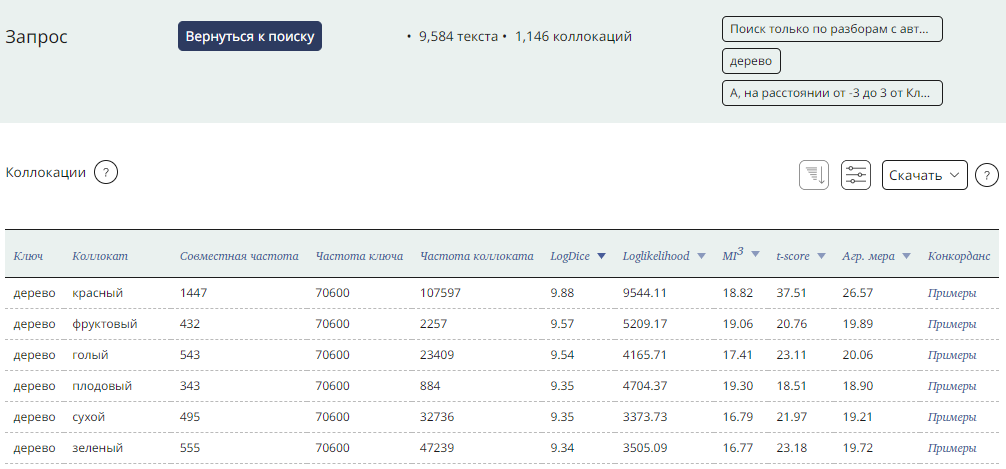
Для поиска коллокаций в корпусе используется статистический подход, то есть коллокациями считаются такие сочетания слов, которые встречаются совместно чаще, чем случайно. Для подсчета коллокаций используются несколько статистических метрик (T-score, logDice, MI3, Loglikelihood). Агрегированная мера показывает геометрическое среднее мер t-score и MI3.
Все формулы подсчетов коллокаций были взяты из онлайн ресурса С.Эверта, посвященного калькуляции ассоциативных мер слов. Если в формуле есть логарифм, то используется натуральный логарифм.
Выдача коллокаций ранжирована: в топ списка попадают слова, наиболее тесно связанные друг с другом.