В виджете Похожие слова отображаются ближайшие семантические ассоциаты слова. Коэффициент близости слов, который можно увидеть наведя мышь на слово в Облаке слов, подсчитывается с помощью моделей дистрибутивной семантики, построенных на актуальных материалах основного корпуса НКРЯ. Чем ближе значение коэффициента к 1, тем крупнее слово в Облаке слов, и тем предположительно более похожими должны быть контексты употребления этого слова на контексты употребления ключевого слова.

Текущая версия Похожих слов работает в Основном, Газетных, Обучающем и некоторых других корпусах и ограничивается выводом семантических ассоциатов той же части речи для существительных, глаголов, прилагательных и наречий. Для имен собственных, топонимов, аббревиатур и слов, имеющие нестандартные написания или редко встречающихся в корпусе, похожие слова не выводятся.
Для поиска слов-ассоциатов в НКРЯ используются обученные на текстах конкретного корпуса word2vec-модели. Для обучения использован алгоритм Continious Bag-of-Words (реализация из библиотеки gensim). Для всех моделей используется размерность вектора 300 и окно в 5 слов. Порог зависит от корпуса и составляет:
- 5 вхождений для Основного, Старорусского корпусов, корпусов «Русская классика», «От 2 до 15» и корпуса Центральных СМИ;
- 7 вхождений для корпуса Региональных СМИ;
- 10 вхождений для Обучающего корпуса.
Скачать векторные модели, обученные на данных корпусов НКРЯ, можно на странице «Нейросетевые модели НКРЯ».
В Портрете слова Основного корпуса можно изучать список слов-ассоциатов не только по всему корпусу, но и по текстам, созданным в определенный период времени. Все тексты Основного корпуса с 1700 по 2022 год поделены на 11 временных периодов. Если количество вхождений слова в тексты выбранного периода ниже порогового значения для корпуса, то похожие слова не выводятся.
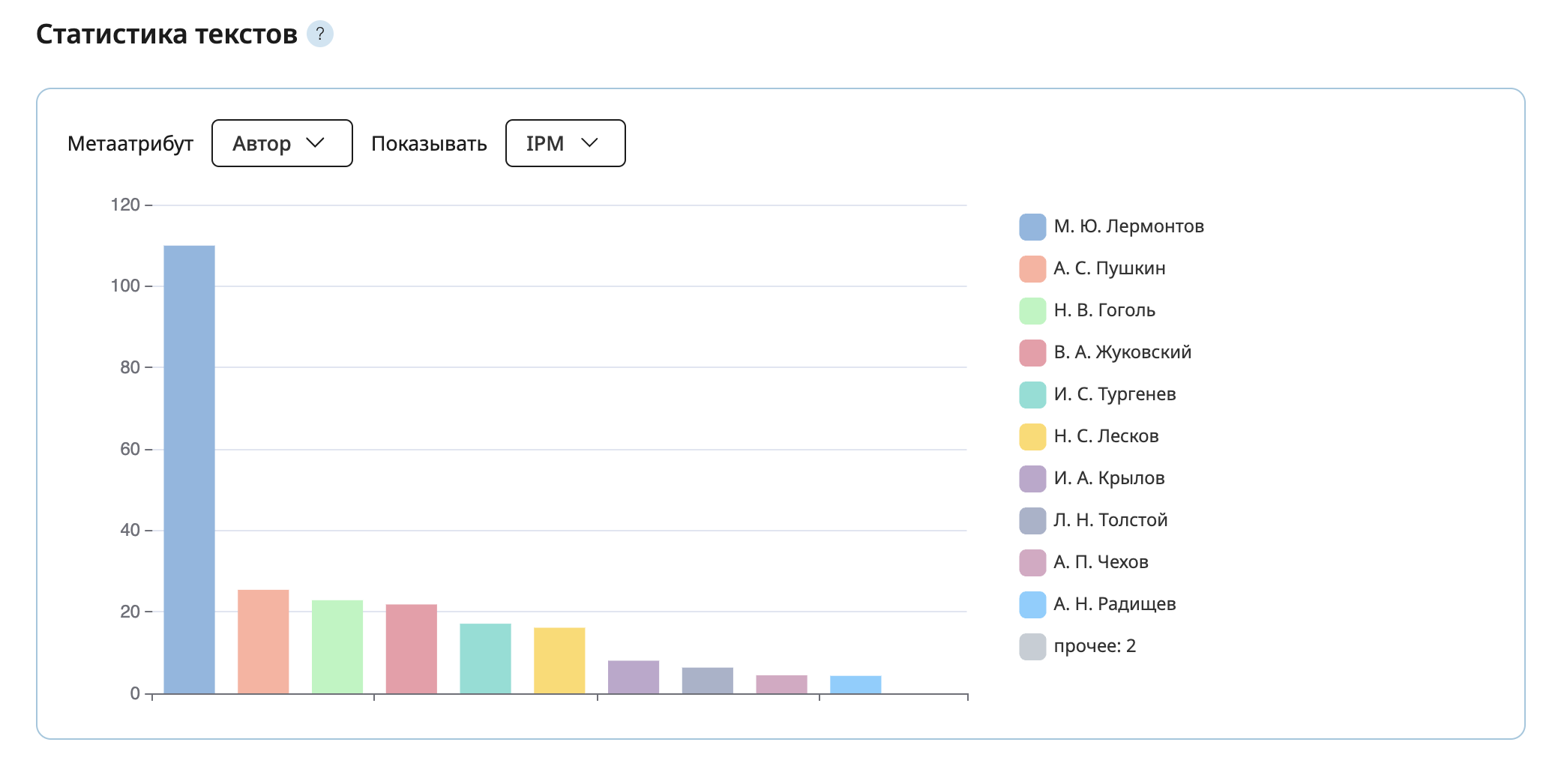
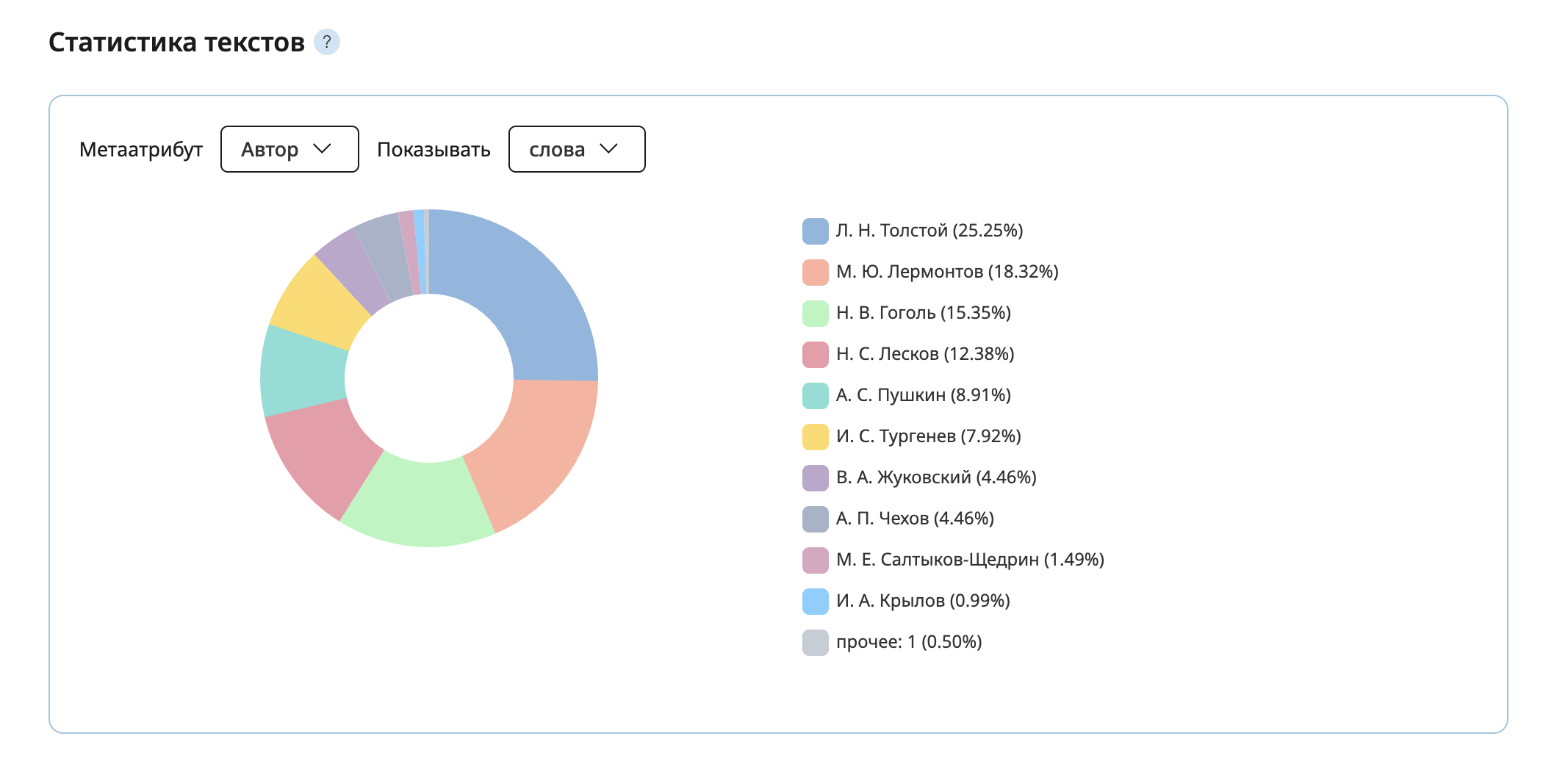
В Портрете слова корпуса «Русская классика β» похожие слова доступны не только для всего корпуса в целом, но и отдельно для произведений 9 авторов, объем сочинений которых достаточно велик. При помощи этого виджета можно сравнивать употребление слова в авторском стиле разных писателей. Если количество вхождений слова во все тексты конкретного автора меньше 7, то похожие слова не выводятся.
Пользователи могут посмотреть на похожие слова одного периода или автора, сравнить два периода или автора, а также скачать скриншот.

Виджет снабжен специальным признаком «сгенерировано НейроКРЯ». Это означает, что выделение ассоциатов происходит полностью автоматически, и в списках могут встречаться ошибки, например неправильно образованные слова, интуитивно не вполне понятные сопоставления слов.