Searching for collocations
Collocations are words that frequently occur together.
To find collocations in the corpus, the statistical approach is used. Sequences of words that occur together more often than by chance are considered collocations. Several statistical metrics are used to find collocations: t-score, logDice, MI3, Loglikelihood. The aggregate measure shows the geometric mean of two measures, T-score and MI3.
All calculation formulae were taken from collocations.de, a website developed by Stefan Evert which lists formulae called association measures. If there is a logarithm in the formula, then a natural logarithm is used.
The output of collocations in the corpora is ranked: the most closely related word associations are listed at the top.
How to search for collocations
To search for collocations, you need to specify a keyword and a collocate.
The keyword is the word for which you need to find the most frequent word combinations. You could either specify a concrete lemma or word form, or set the desired grammatical, semantic and/or syntactic features.
The collocate is a word that forms a collocation together with the keyword. You can specify a lemma, a word form, or a combination of grammatical, semantic and/or syntactic, or use the wildcard *.
You can set the distance between the key and the collocate (no more than five words). This means that we are looking for collocates that occur more often than by chance from the key at a given distance. If you want to find collocates that precede the word in the sentence, then the distance must be specified as a negative number. For example, in Russian normally the adjective comes before the noun. To find all adjectives that are associated with the word дерево (“tree”), you should set дерево as the keyword in your search query, select the grammatical feature “adjective” for the collocate, and set the distance from -1 to -1.
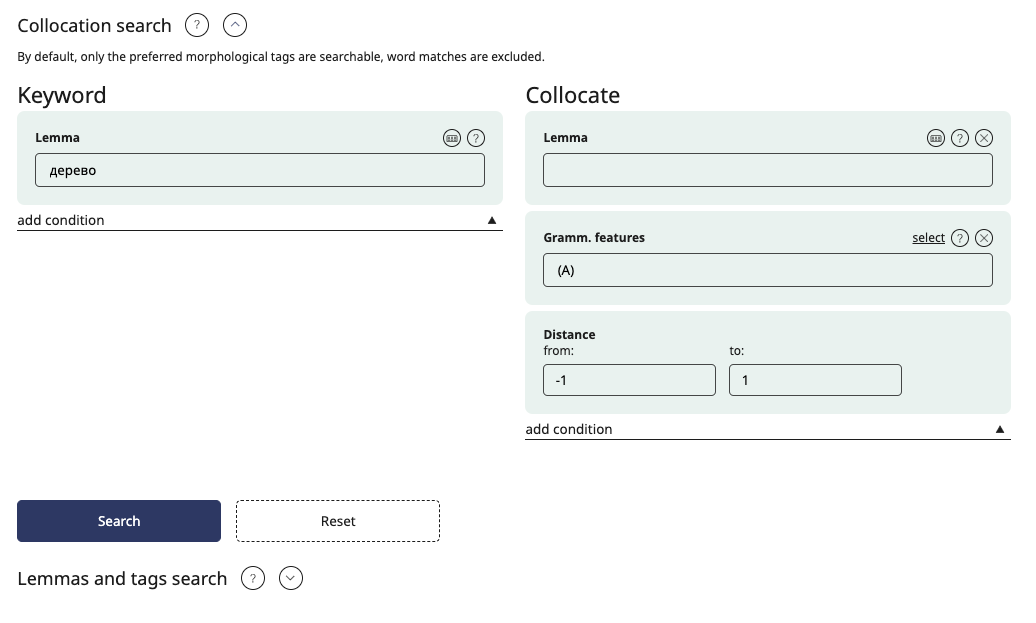
The collocations are searched only in the automatically disambiguated texts. Zero distances between words are not taken into account, that is, when searching for identical words at any distance from each other, there will be no examples among the results in which the word occurs only 1 time.
Learn how to search for collocations in the video tutorials
Calculation of collocations
Each of the collocation metrics is calculated differently and gives a different ranking of collocates. For example, when using the MI3 metric, rare collocations get the highest score, whereas when using the t-score, the ranking turns out to be essentially similar to the simple ranking by frequency.
For the calculation of each of the metrics, four values are used:
w1 is the number of occurrences of the keyword in the corpus or subcorpus
w2 is the number of occurrences of the potential collocate in the corpus or subcorpus
w1w2 - the number of occurrences of the keyword + collocate combination in the corpus or subcorpus
N is the size of the corpus or subcorpus.
Below are the formulas used for calculating collocation metrics.
LogDice
$$14 + \log \left( \frac{2 w_{12}}{w_1 + w_2} \right)$$
Loglikelihood
$$2 \left( w_{12} \log \left( \frac{w_{12} N}{w_1 w_2} \right) + (w_1 - w_{12}) \log \left( \frac{(w_1 - w_{12}) N}{w_1 (N - w_2)} \right) + (w_2 - w_{12}) \log \left( \frac{(w_2 - w_{12}) N}{(N - w_1) w_2} \right) + (N - w_1 - w_2 + w_{12}) \log \left( \frac{(N - w_1 - w_2 + w_{12}) N}{(N - w_1) (N - w_2)} \right) \right)$$
MI3
$$log \left( \frac{N w_{12}^3}{w_1 w_2} \right)$$
t-score
$$\frac{w_{12} - \frac{w_1 w_2}{N}}{\sqrt{w_{12}}}$$
Aggregated measure
$$\sqrt{ \max\left(0, \frac{w_{12} - \frac{w_1 w_2}{N}}{\sqrt{w_{12}}}\right) \cdot \max\left(0, \log \left( \frac{N w_{12}^3}{w_1 w_2} \right) \right)}$$
Presenting the found collocations
The resulting value of each of the metrics is shown in a table in the corresponding column. The collocations are always shown as two lemmas.
The output of collocations in the corpora is ranked: the most closely related word associations are listed at the top.
You can select a column for ranking (for example, one of the metrics, or the aggregated measure).
No more than 100 collocations are shown on one screen.
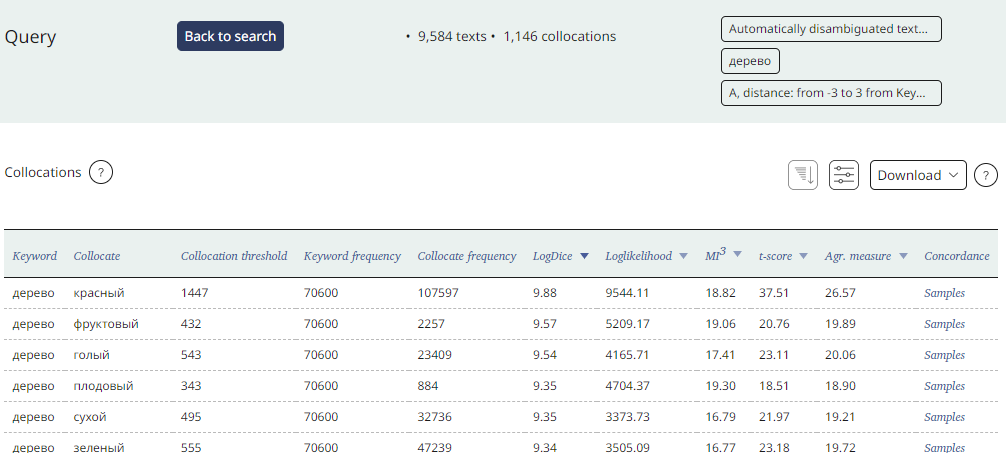
Collocations can also be downloaded in a XLS or CSV file, whose size is limited to 5000 units.
Settings
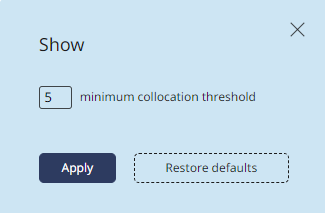
You can set a threshold for the occurencies of the keyword and the collocated together in the Settings menu. By default, it is set to 5. This means that the list will only include collocations that occur no less than 5 times in the corpus. Thus you can filter out occasional word sequences. But if you get too few or no results at all, you can lower the threshold to include less frequent collocations.
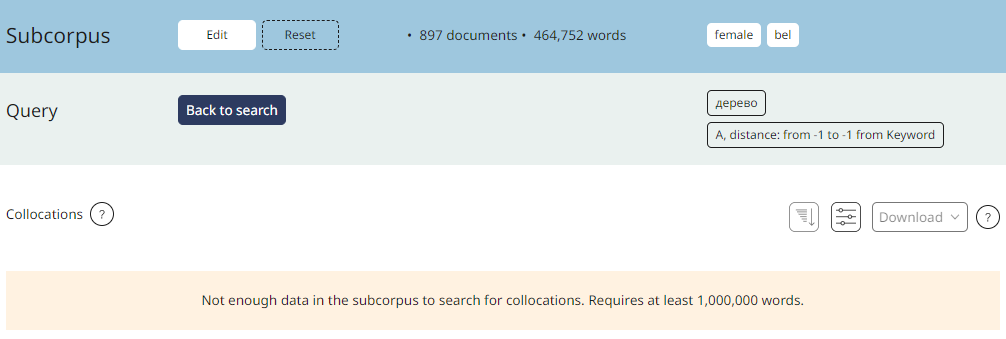
If you set a user's subcorpus, you will not be able to search for collocations unless the size of your subcorpus is more than 1 million words. Smaller size corpora are not sufficient to get relevant collocations.
Currently, searching for collocations is available for the Main, Educational, Media and some other corpora. Later it will be added to more corpora.