The Frequency dictionary shows which words occur most frequently in the corpus or in the user's subcorpus. It is part of the Corpus portrait or Subcorpus portrait. You can find it in the About (i) section of the respective corpus or subcorpus.
Frequency dictionaries
Frequency dictionary of the corpus
The frequency dictionary is a list of 500 most frequent lemmas of the corpus with the option to select only nouns, adjectives, verbs or adverbs.
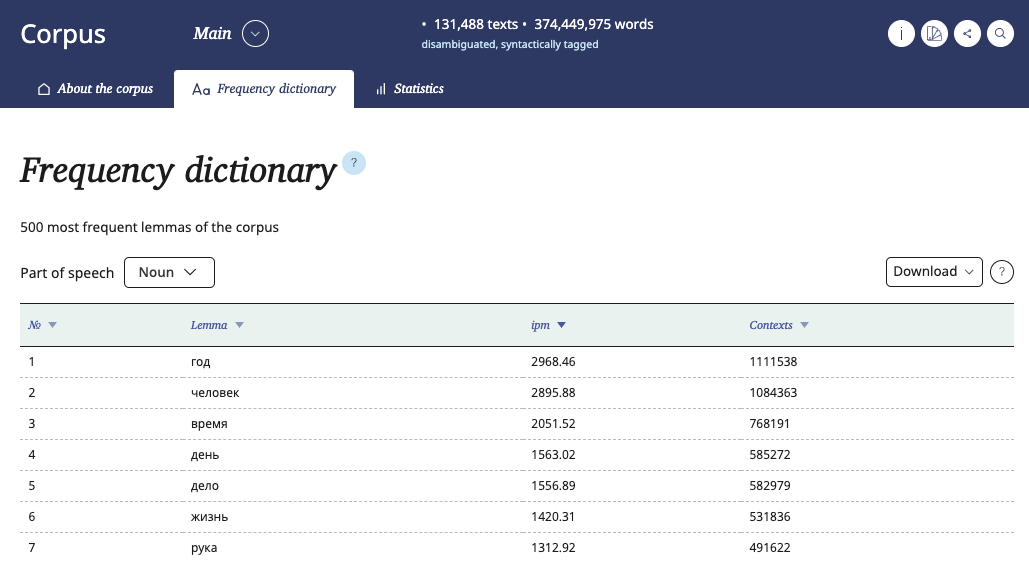
This is a table with four columns: the rank of the lemma by frequency of occurrence (from 1 to 500), the lemma itself, its relative frequency (ipm) and its absolute frequency.
Data in each column can be sorted in ascending or descending order.
Subcorpus frequency dictionary
The subcorpus frequency dictionary makes it possible to compare the contents of the user's subcorpus and the original corpus: the table includes the subcorpus frequency list and the corpus frequency list.
These two lists are linked through the ranks of the subcorpus frequency dictionary lemmas.
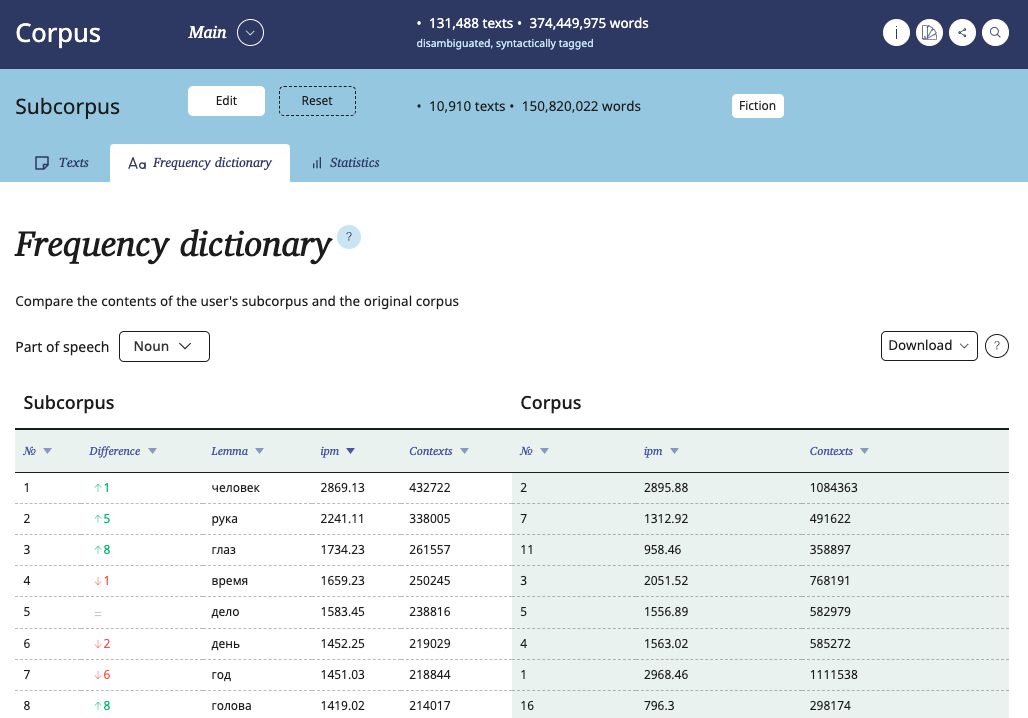
Using the selector located above the table, you can choose all lemmas or only nouns, adjectives, verbs or adverbs.
The subcorpus Rank and Difference columns contain information not only about the position of the lemma in this frequency list, but also how it has changed relative to the original corpus: went up or down. For each of the 500 most frequent lemmas of the subcorpus, you can see how often they occur in the original corpus and compare information about their relative and absolute frequencies in the corpus and subcorpus. If a lemma from the subcorpus frequency list turns out to be of low frequency in the original corpus, then its rank there is defined as "> 500".
Such a comparison tool provides information about the lexical specificity of the documents of the selected subcorpus in comparison with the balanced original corpus.
Download as a file
Press the Download button in the search results menu to download the frequency dictionary in Excel or CSV format.
The size of the file is limited to 500 lemmas.
Currently frequency dictionaries are available in the Main, Educational, Media and some other corpora. Later on, this feature will be added to more corpora.
Updated on 30.09.2025