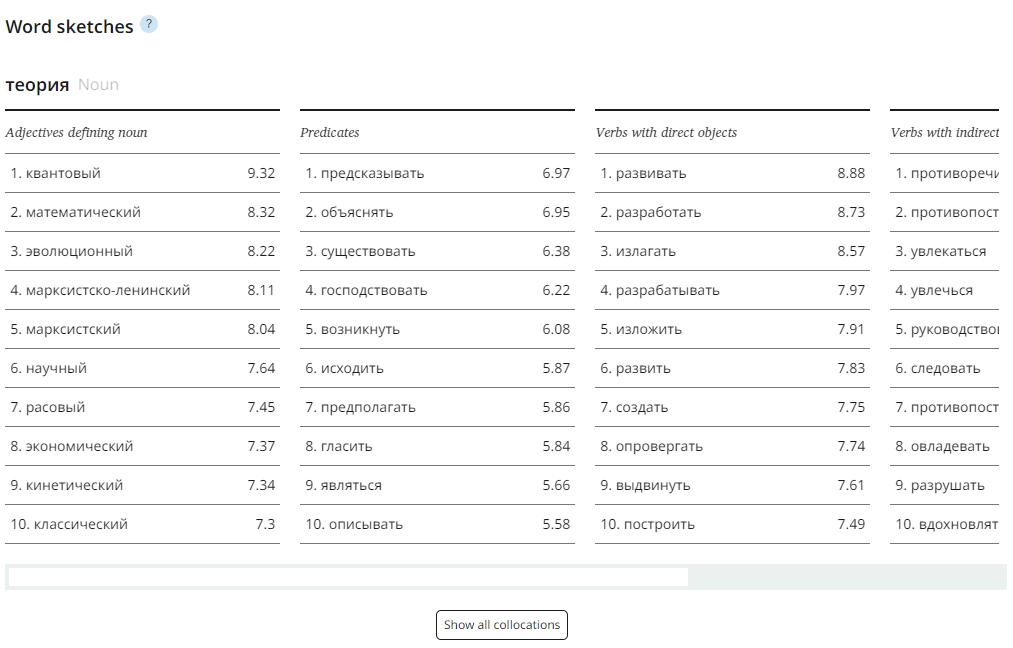
The Similar words widget displays the closest semantic associates of the word. The proximity coefficient of words, which can be seen by hovering the mouse over a word in the Word cloud, is calculated using distributive semantics models based on the actual materials of the main corpus of the RNC. The closer the coefficient value is to 1, the larger the word in the Word cloud is, and the more similar the contexts with this word should be to the contexts with the keyword.

The current version of Similar words works only in the Main, Media, Educational, and some other corpora and only shows semantic associates of the same part of speech for nouns, verbs, adjectives and adverbs. For proper names, toponyms, abbreviations and words that have non-standard spellings or are rarely found in the corpus, similar words are not displayed.
We use word2vec models trained on texts of a specific corpus to search for word associates in RNC. Currently, models have been trained for seven corpora: Main, Media, Educational, Middle Russian, “Russian Classics” and “From 2 to 15”. The Continuous Bag-of-Words algorithm (implementation from the gensim library) was used for training. All models use a vector dimension of 300 and a window of 5 words. The threshold depends on the case and is:
- 5 entries for the Main, Middle Russian, “Russian Classics”, “From 2 to 15” corpora and the corpus of Central Media;
- 7 entries for the Regional Media corpus;
- 10 entries for the Educational corpus.
You can download the vector models trained on the RNC corpora data from the “The RNC neural network models” page.
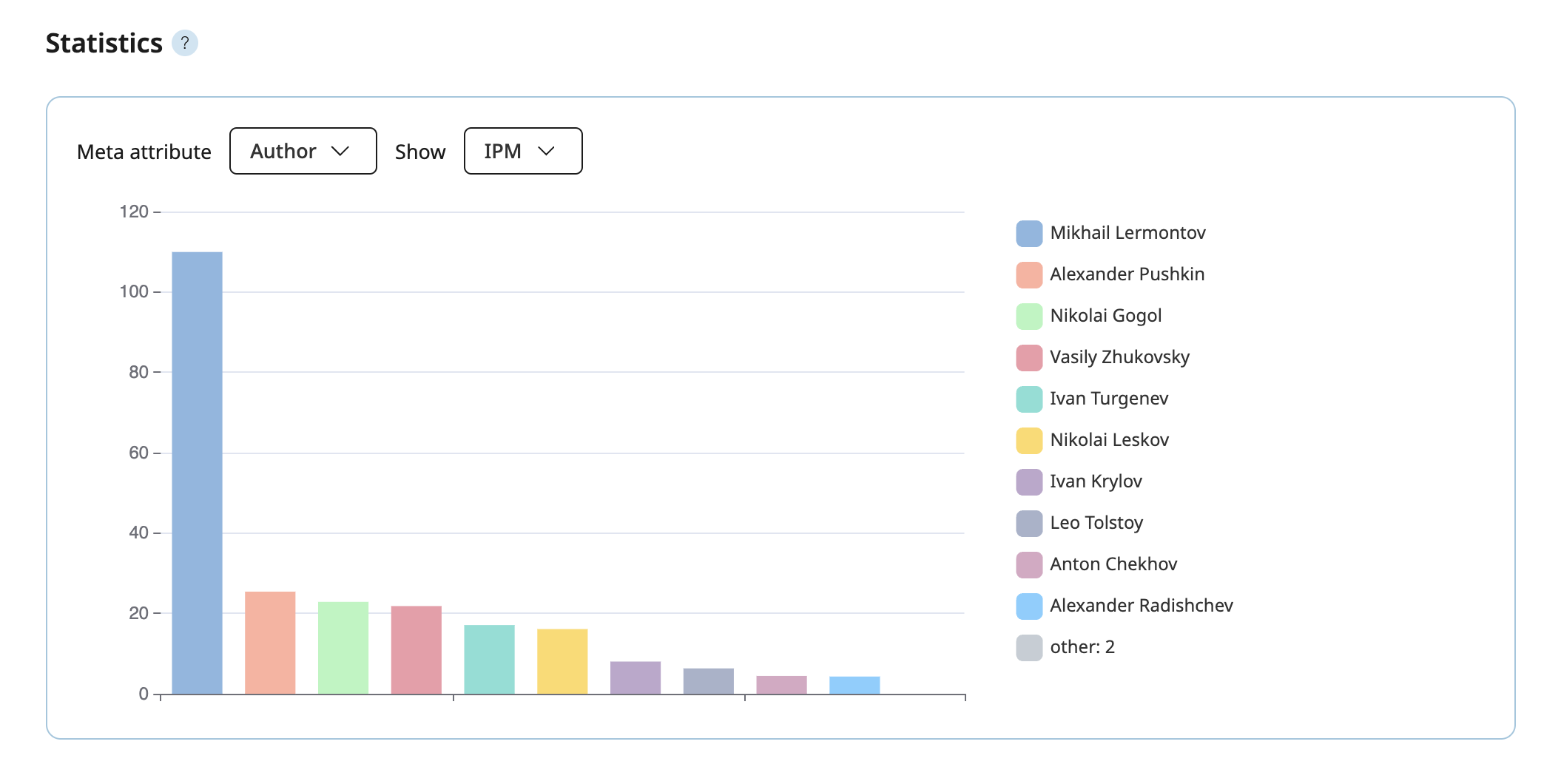
With "Similar Words" widget at the Main corpus users can now examine context-based associated words not just across the entire corpus but within specific historical periods. All texts within the Main Corpus (1700–2020s) have been divided into 11 time spans. If the number of occurrences of a word in the texts of the selected period is lower than the threshold for the corpus, similar words are not displayed.
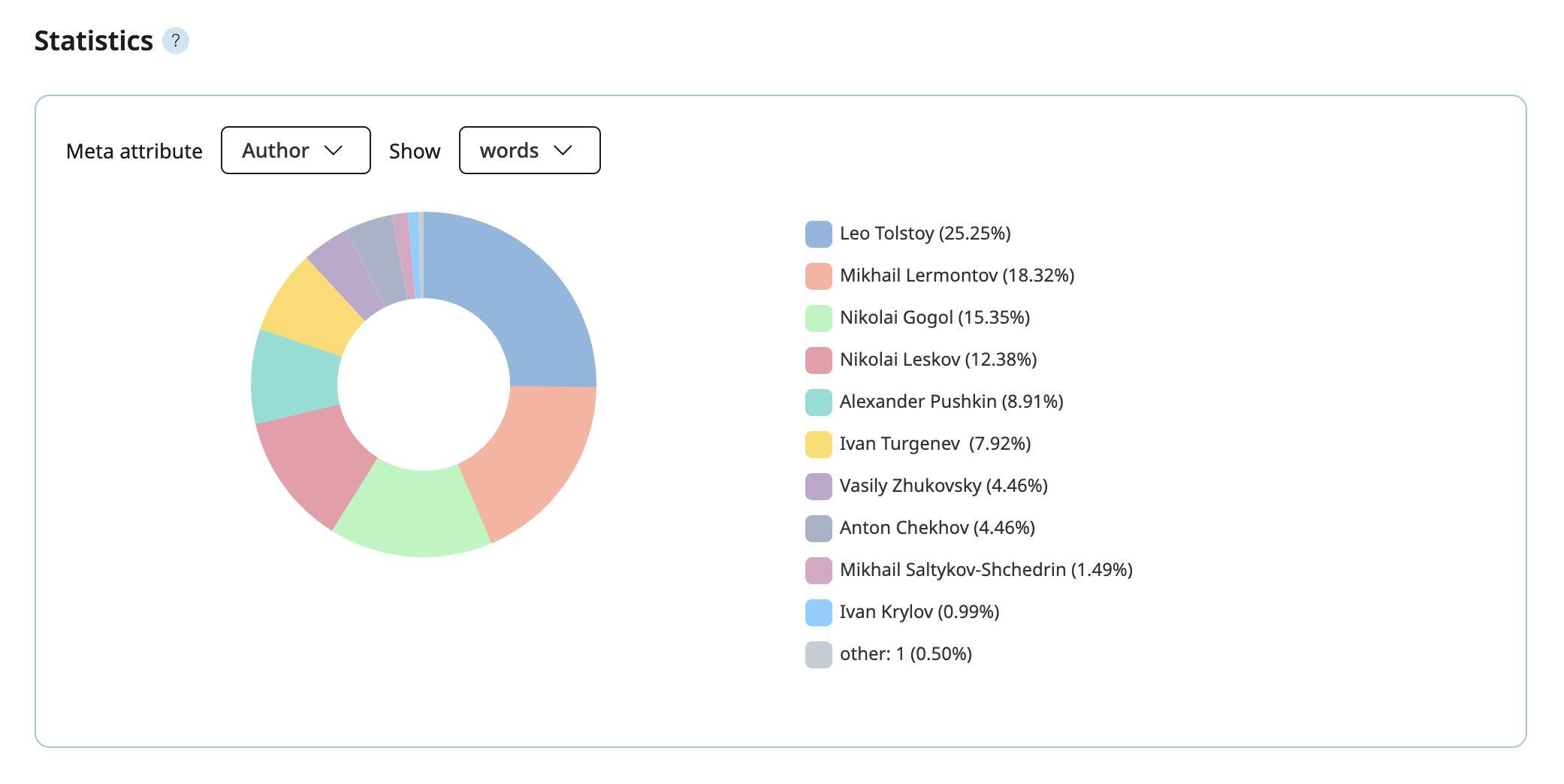
The "Similar Words" service in "Russian classics β" corpus is available not only for the entire corpus, but also individually for works by nine authors whose corpora are the most extensive. This feature allows users to compare how a word is used across the distinctive individual styles of different writers. If the number of occurrences of a word in the texts of the author is less than 7, similar words are not displayed.
Users can view similar words from a single time span or one author, compare word clouds across two different time spans or two authors, and download a screenshot of the results.

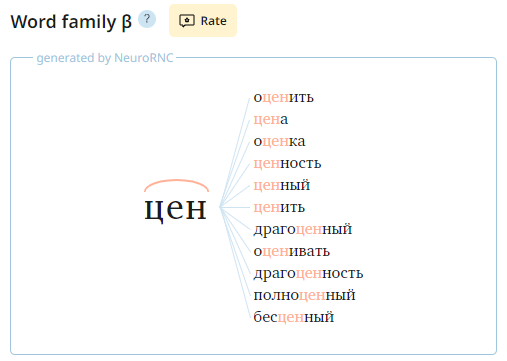
The widget is marked with a special sign "Generated by NeuroRNC". It means, the selection of associates is completely automatical and errors may occur in the lists, for example, incorrectly formed words or word associations that are not intuitively clear.