НКРЯ предоставляет пользователю возможность увидеть результаты поиска в нескольких форматах. Во всех корпусах доступны виды выдачи Конкорданс и KWIC, другие виды выдачи опциональны.
Виды выдачи
Конкорданс
В режиме Конкорданс найденные примеры сгруппированы по текстам, в которых они обнаружены.

В параллельных корпусах примеры выводятся в два столбца. Слева вы увидите фрагмент текста на языке оригинала, а справа сможете выбрать один из переводов.
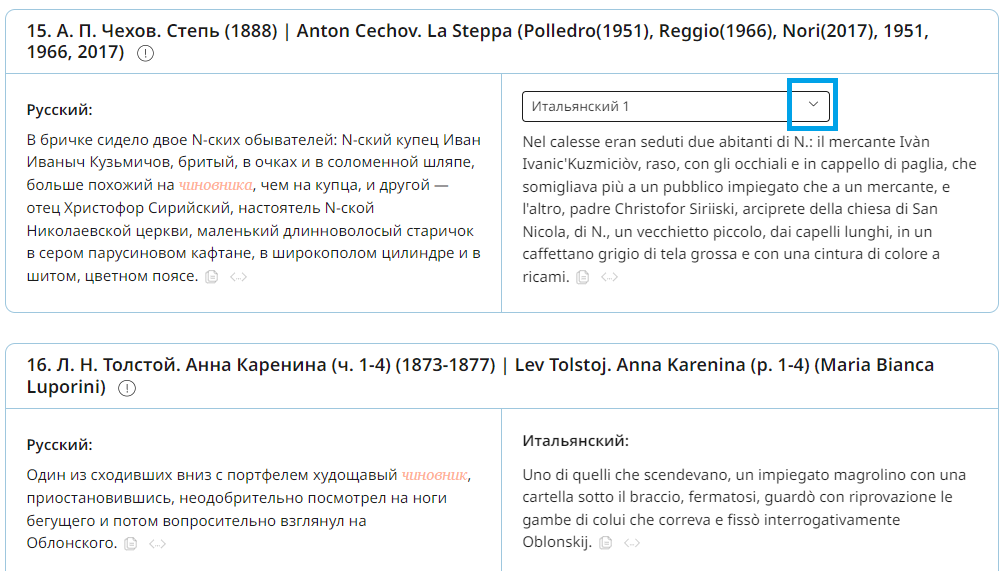
В диалектном и мультимедийных корпусах примеры сопровождаются паралельными видео или аудио фрагментами. Таблица жестов отображается, если жесты размечены.
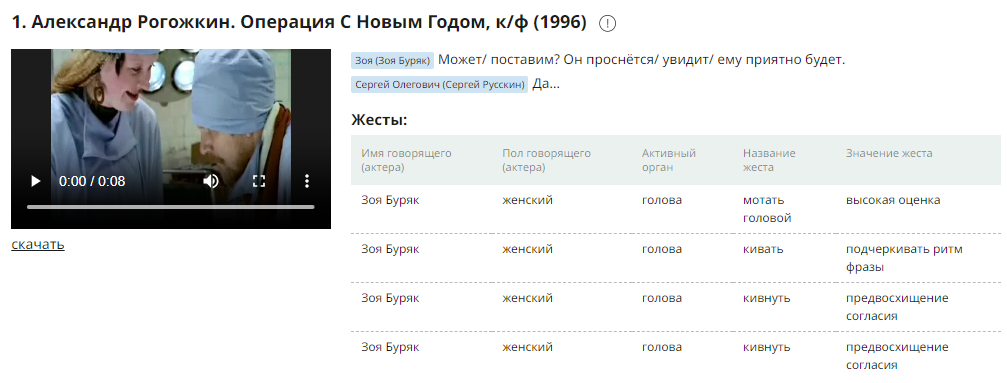
С помощью настроек пользователь может управлять количеством документов на странице и количеством примеров в каждом документе, которые выводятся на экран.
Подробнее о работе с примерами см. раздел Анализ результатов поиска.
KWIC
В режиме KWIC (Key Word in Context – ключевое слово в контексте) в каждом примере явно выделено центральное слово. Слова, расположенные левее и правее этого слова, формируют его левый и правый контекст.

В режиме KWIC доступны дополнительные способы сортировки по левому и правому контексту.
Пользователь может выбирать центральное слово самостоятельно, переключаясь между словами поискового запроса на полоcе Запрос. Текущее центральное слово выделено оранжевым цветом и отмечено галочкой.

Подробнее о работе с примерами см. раздел Анализ результатов поиска.
График
В ряде корпусов доступен режим просмотра распределения результатов во времени (частота на миллион словоформ). В корпусе региональных СМИ детализация графиков возможна по дням, месяцам и годам, в других корпусах - только по годам.
Пользователь может воспользоваться готовым графиком или уточнить отображение результатов выдачи, изменив период времени или сглаживание.
В некоторых корпусах под графиком можно увидеть тепловую шкалу, демонстрирующую количество текстов, в которых найдены примеры.
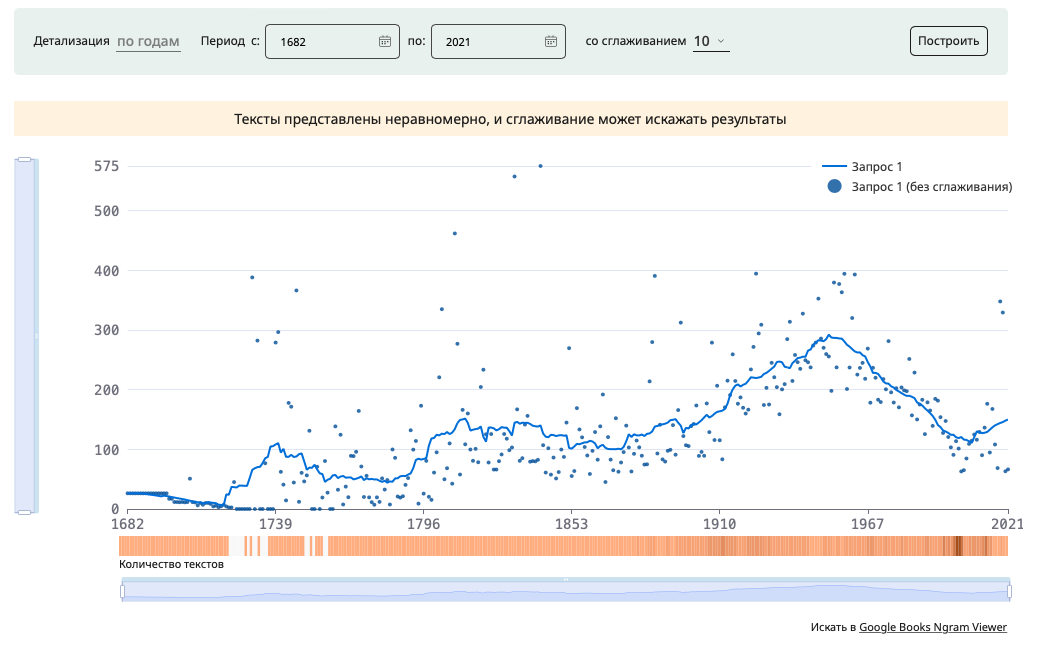
Нажав на «Скачать» пользователь может скачать график как картинку.
Подробнее об анализе графиков см в статье Хронологическое распределение результатов поиска.
Статистика
В режиме выдачи Статистика показано распределение найденных текстов по значениям нескольких метаатрибутов. Например, по Авторам, Типам текстов или Жанрам.
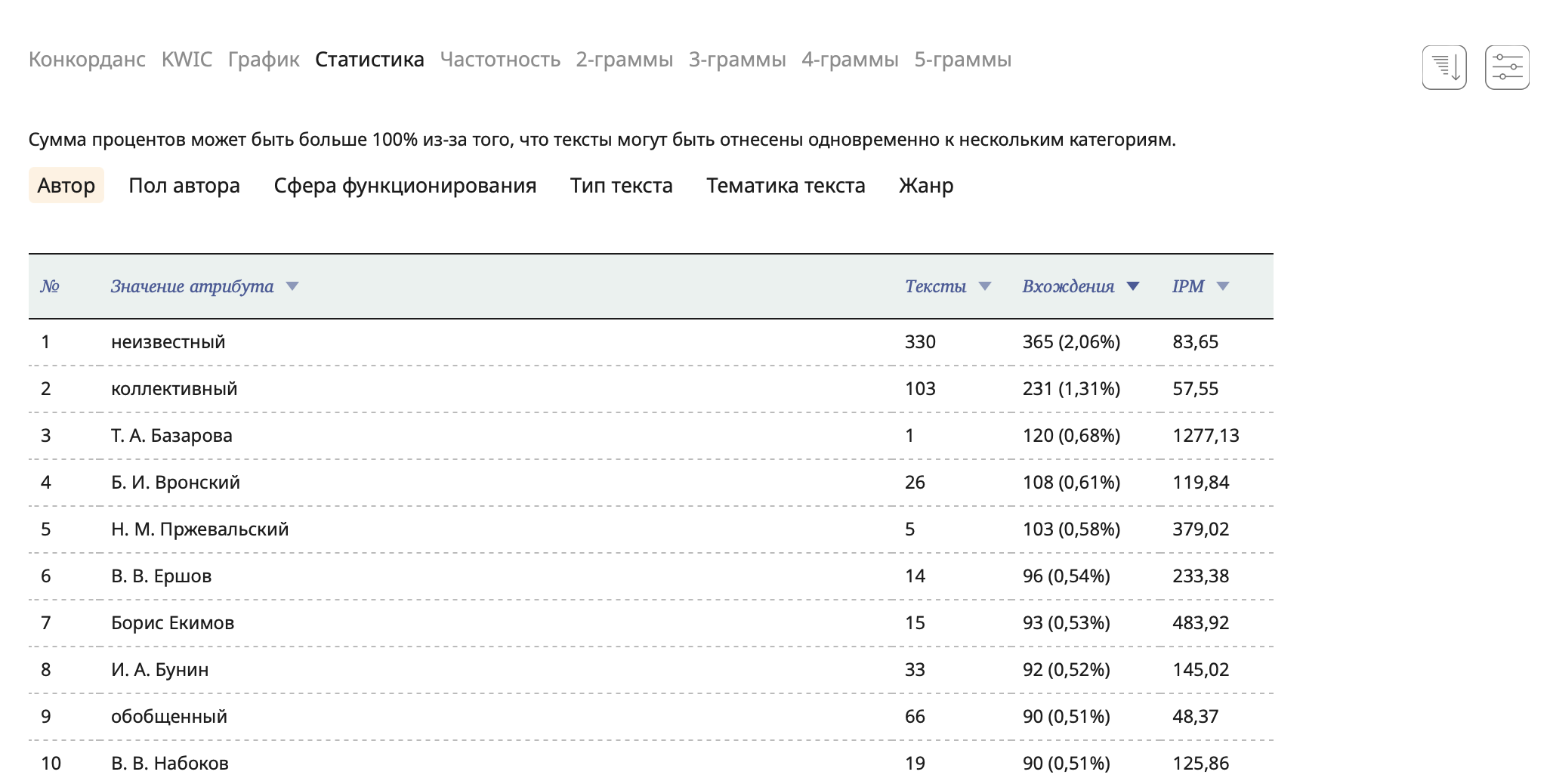
В каждом корпусе набор таблиц, приведенных в Статистике, разный и определяется тем, какие атрибуты наиболее полно характеризуют тексты корпуса.
По умолчанию таблица отсортирована по количеству вхождений. Чтобы изменить критерий сортировки, кликните на название колонки.
В настоящий момент вид выдачи Статистика доступен в Основном, Обучающем и некоторых других корпусах. В дальнейшем список таких корпусов будет расширяться.
Частотность
Вид выдачи Частотность отражает частотное распределение результатов поиска. В таблице частотности можно увидеть, какие словоформы, леммы или наборы грамматических признаков чаще всего соответствуют заданным условиям запроса в результатах поиска.
Такая выдача может быть особенно информативной, если запрос содержит в себе лексико-грамматические условия на несколько слов с заданными расстояниями между ними. Например, можно найти сочетания прилагательного и существительного, которые находятся на расстоянии от -1 до 1 друг от друга, то есть располагаются в любом порядке. Распределение 100 самых часто встречающихся сочетаний будет показано в таблице.
В настоящий момент вид выдачи Частотность доступен в Основном, Обучающем, Газетных и некоторых других корпусах. В дальнейшем список таких корпусов будет расширяться.
N-граммы
N-граммы — это последовательности из n слов, включающих слова запроса пользователя. Например, для запроса из двух слов будут показаны биграммы— последовательности из двух слов запроса, 3-граммы — два слова запроса и третье слово в сочетании с ними, 4-граммы — два слова запроса и два других слова.

В выдаче n-граммы распределены по убыванию IPM - в начале списка показаны самые частотные последовательности. В таблице n-грамм приводятся число документов, в которых встретилась n-грамма, число вхождений, частота ее встречаемости на миллион словоупотреблений данного корпуса и собственно n-грамма со ссылкой на примеры в корпусе.
В настоящее время n-граммы строятся только по словоформам. N-граммы для лемм будут доступны в рамках нового вида выдачи Частотность, который находится в стадии разработки.
Вид выдачи N-граммы сейчас доступен в Основном, Обучающем, Газетных и некоторых других корпусах. В дальнейшем список корпусов будет расширяться.
Вид выдачи по умолчанию
По умолчанию всем пользователям отображаются результаты поиска в режиме Конкорданс, при этом можно переключиться на другой доступный в корпусе вид выдачи с помощью меню видов выдачи.

Продвинутые пользователи могут выбрать предпочтительный для себя вид выдачи с помощью меню на кнопке Искать. Мы запомним выбранный вид выдачи в браузере пользователя и будем в дальнейшем сразу открывать его.
Обновлено 30.09.2025