RNC News
The Middle Russian corpus has been enlarged by 500 thousand tokens. Texts of different genres and time periods have been added to the corpus, from the Pskov gramoty of the fourteenth and fifteenth centuries surviving in late copies to the early documents of Peter the Great and treatises in rhetoric of the 1690s. In addition, the Commission copy of the Novgorod First Chronicle, collections of peasant petitions and Muscovite diplomatic correspondence with Germany and the Crimean Tatars are now available for searching. The morphological analysis of the text has been significantly upgraded: the corpus dictionary has grown by about 40 000 lexemes.

More search results are now available in Frequency mode, and even more can be downloaded as a spreadsheet. This is a feature of major importance for the researcher who is interested not only in the most common variants, but also in a broader picture. A spreadsheet (Excel or CSV) now shows the top 1000 most frequent query results. Up to 5000 output results with frequency data can be downloaded. Read more about this and other types of output in the User Guide.
When downloaded in the Excel format, the Info tab now shows the exact number of both found and downloaded documents and examples. Thus the user can evaluate the output results more accurately and interpret them correctly.
Diachronic subcorpus statistics have been added to the Main and Regional corpora. Now you can compare graphs characterizing the size and composition of texts in a subcorpus, changing over time, with texts of the whole corpus. For example, one can see that women authors in the 19th century write relatively more fiction than texts in other genres, and the situation levels off in the twentieth century.
You can set the distribution, dates, and smoothing of frequencies. To see the charts of diachronic statistics, you need to click on the (i) button in the subcorpus header, select the Statistics section, and navigate to the Diachronic statistics tab.
From the tooltip, you can learn how to use the new charts and graphs and how to interpret the obtained results.
Earlier in February, diachronic statistics of the Main and Regional corpora became available to users.

In the Word at a glance widget, you can now examine the ratio of the number of occurrences of a word in a category to the size of that category multiplied by a million (instance per million, or ipm). With this widget you can determine, for example, whether Leo Tolstoy really used the word мир ‘peace’/’world’ more often than other Russian classics, taking into account the overall size of their texts. Yet another question: which romantic poet mentions всадник ‘horsemen’ more, Lermontov or Pushkin?
The new chart is available in the Statistics widget of the Word at a glance. The user can select the meta-attribute for which the chart is to be plotted from the list of the most representative attributes of the corpus. To see a pie chart containing the exact number of contexts of a word in a category or the number of texts containing the searched word, one has to switch from ipm to words or texts.
In addition, in the “Statistics” mode, the ipm information in the table has appeared. By default, the table is sorted by the number of occurrences. To change the sorting criterion, click on the column name.

In the Social Networks corpus the annotation of sentiment has been added. Now texts of positive or negative sentiment can be selected for research. Texts where sentiment could not be determined are categorized as undefined.
Sentiment labeling in the “Social Networks” corpus appeared thanks to the Friends of NeuroRNC. They helped us to collect data for the training dataset, so that we could train the neural network model, and then label the texts of the corpus. A field in the subcorpus form and in the text information is marked with a special icon indicating that the values for the attribute were generated by NeuroRNC.
Errors may occur in the automatic sentiment annotation. If you find them, please let us know using the “Report an error” button in the text information. This will help us to improve the quality of the annotation.
The Old East Slavic corpus was expanded by more than 31 thousand tokens. The update includes, in particular, such literary texts as The Tale of the Destruction of Rus and Zadonshchina, as well as official documents: The Church Statute of Prince Yaroslav and legal acts (gramoty) of the 13th-15th centuries from Ukraine, Moldova, Lithuanian-Belarusian lands, Smolensk, Novgorod, Pskov and Moscow. The corpus' vocabulary has been expanded by almost a thousand lexemes, including earlier references to such modern words as чемодан ‘suitcase’, таможенник ‘customs officer’ and странствие ‘wandering’.
The Similar Words widget has appeared in the Word at a glance in the Old Russian Corpus. As in other corpora where the widget is available, the closest semantic associates of a word are generated automatically. The model used to search for associated words within the Old East Slavic corpus, as well as the updated vector space models for the Middle Russian corpus, are available for downloading in the RNC Neural network models section.

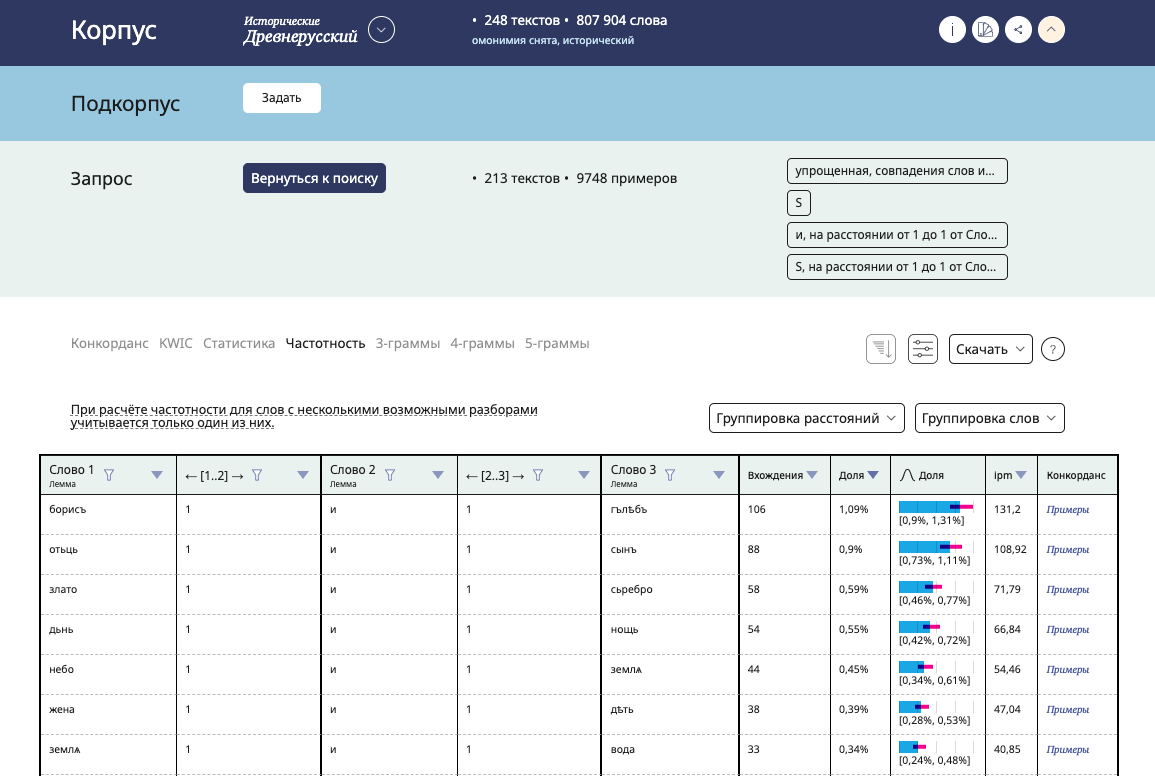
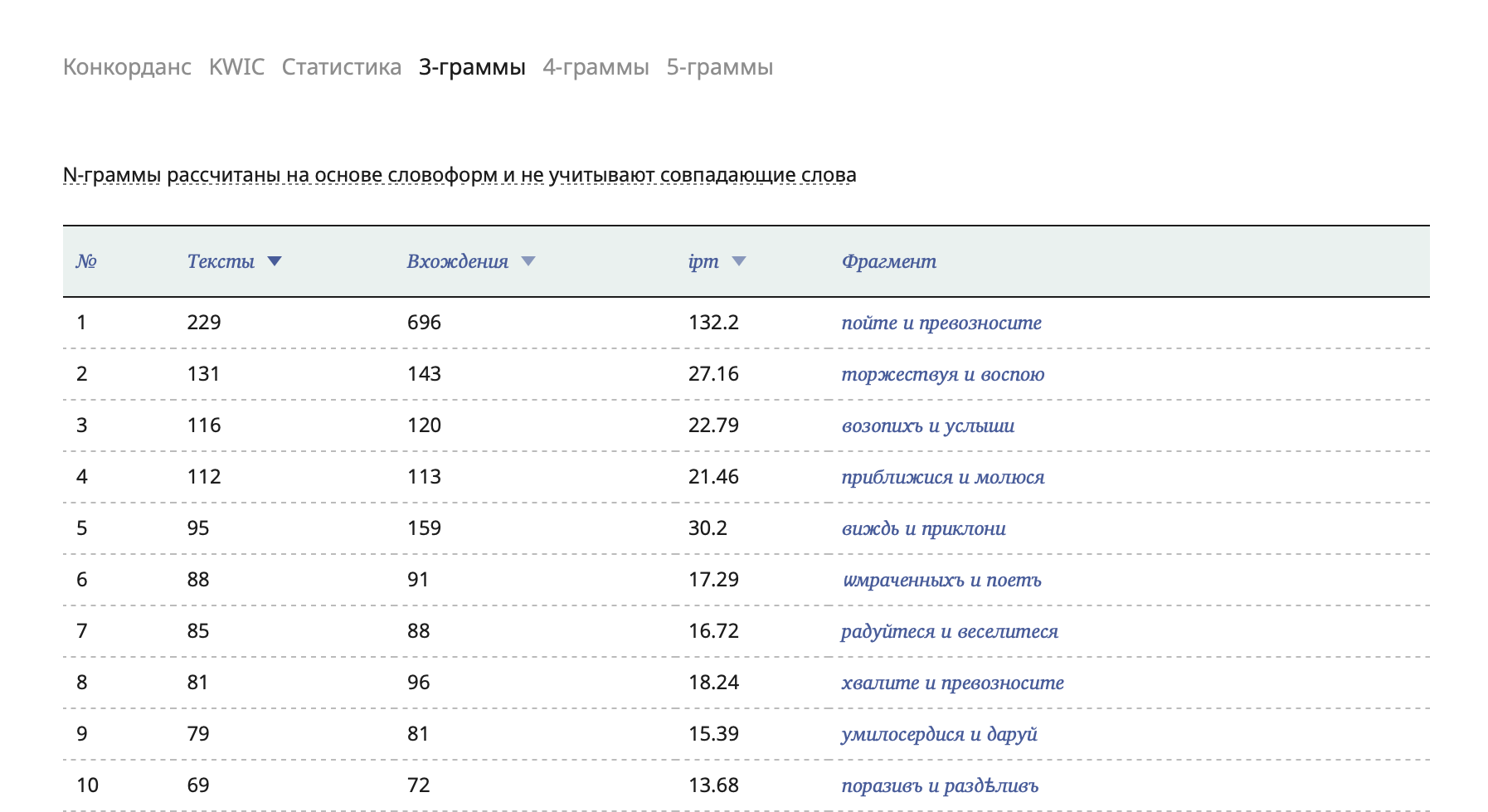
In May, we significantly upgraded several corpora at once: Middle Russian, Church Slavonic and Spoken. They now feature new types of search results, such as Frequency, Statistics, and n-grams. With the new functionality you can find out, for example, which combinations of verbs in liturgical texts occur more often: пойте и превозносите ‘sing and exalt’ or радуйтеся и веселитеся ‘rejoice and be merry’, as well as determine which imperatives have рука ‘hand’ as an object.
Statistics also appeared in Word at a glance and Сorpus portrait. Users of the Middle Russian, Church Slavonic and Spoken Corpora can also customize downloading search results and sort them in KWIC mode.
Users can now search lemmas and forms with regular expressions in all these corpora, as well as in the Old East Slavic corpus, the "Russian Classics" and "From 2 to 15" corpora.
The Russian National Corpus celebrates its 20th anniversary!
On April 29, 2004, the RNC website was opened for free access. But the creation of the RNC began much earlier, back in 2000. It is symbolic that the official "birthday" of the Corpus is on April 29 – the birthday of the Russian linguist, author of the Grammatical Dictionary of the Russian language A. A. Zaliznyak (1935-2017).
It all started with the idea of creating a complete collection of texts that would be culturally representative and reflect the diversity of prose written between 1965 and 2000. Currently, the RNC consists of 49 corpora with a total volume of more than two billion tokens. For 20 years, the Corpus has become an indispensable tool for linguists, teachers, students and anyone interested in the Russian language.
Congratulations to the creators of the RNC and those who help it develop! Thanks to you, the Corpus continues to grow and improve, providing new opportunities for learning the Russian language.
For those who are interested in learning more about the history and modern capabilities of the Corpus, we have prepared a set of materials:
- Explore how the corpus looked 20 years ago, in the RNC Museum.
- Immerse yourself in the history of the creation and development of the RNC in a special project of the “Bolshoy gorod”.
- Read the User Guide and learn how to use the corpus for different tasks.
- Explore the publications about the RNC in the recently updated section. We recommend paying attention to the recent publication on the fundamental reconstruction and modernization of the RNC platform.
- Download and apply neural network models, which are used to mark up words and texts of the Corpus, for your own tasks
- Find out how to get the offline version of the Corpus for research.
Those who want to participate in the development of the corpus are invited to join the group «Друзья НейроКРЯ». You will be the first to learn about upcoming projects and will be able to participate in them. Recently, we launched a new experiment to find out which definitions of words are better perceived by users: taken from dictionaries or generated by a neural network.

A new section is now available on the Corpus website. It describes the RNC neural network models used for annotating words and texts within the Corpus.
The users have access to the following tool:
- the tokenizer
- vector space models searching word associates and customized for 7 domains
- models for morphemic annotation
- models for annotating genre, topic, and type of text
The new section will be useful for everyone who is interested in natural language processing and wants to learn more about what machine learning technologies are used in RNC. Users can consult descriptions of the models or download them for their own use. Before downloading a model please read the license agreement and accept its terms.
In April, the Old East Slavic corpus was considerably upgraded. It now features new types of search results, such as Frequency, Statistics, and n-grams. Using the Frequency feature users can build frequency lists of tokens and constructions. For example, one can check which nouns are coordinated most often in the corpus of the Early Medieval texts (‘Boris and Gleb’, ‘fear and trembling’ and others). The query results can be sorted by context. Frequency dictionaries are available while customizing subcorpus, and they can be compared to the lexical frequencies of the whole corpus.
The arrival of new functionality expands the possibilities of using the corpus and automates routine processes that previously took considerable time.