RNC News
We continue to roll out new functionality already available in the advanced corpora, such as Main, Media, and Learning, to other corpora. An improved version of the “From 2 to 15” corpus is now available to users of the RNC. All the texts within the corpus feature resolved grammatical homonymy and syntactic annotation. Syntactic relations search and collocation search are now available, as well as new output types such as frequency, n-grams, statistics.
The Word at a Glance function has been updated, and new types of sorting by context have been added.
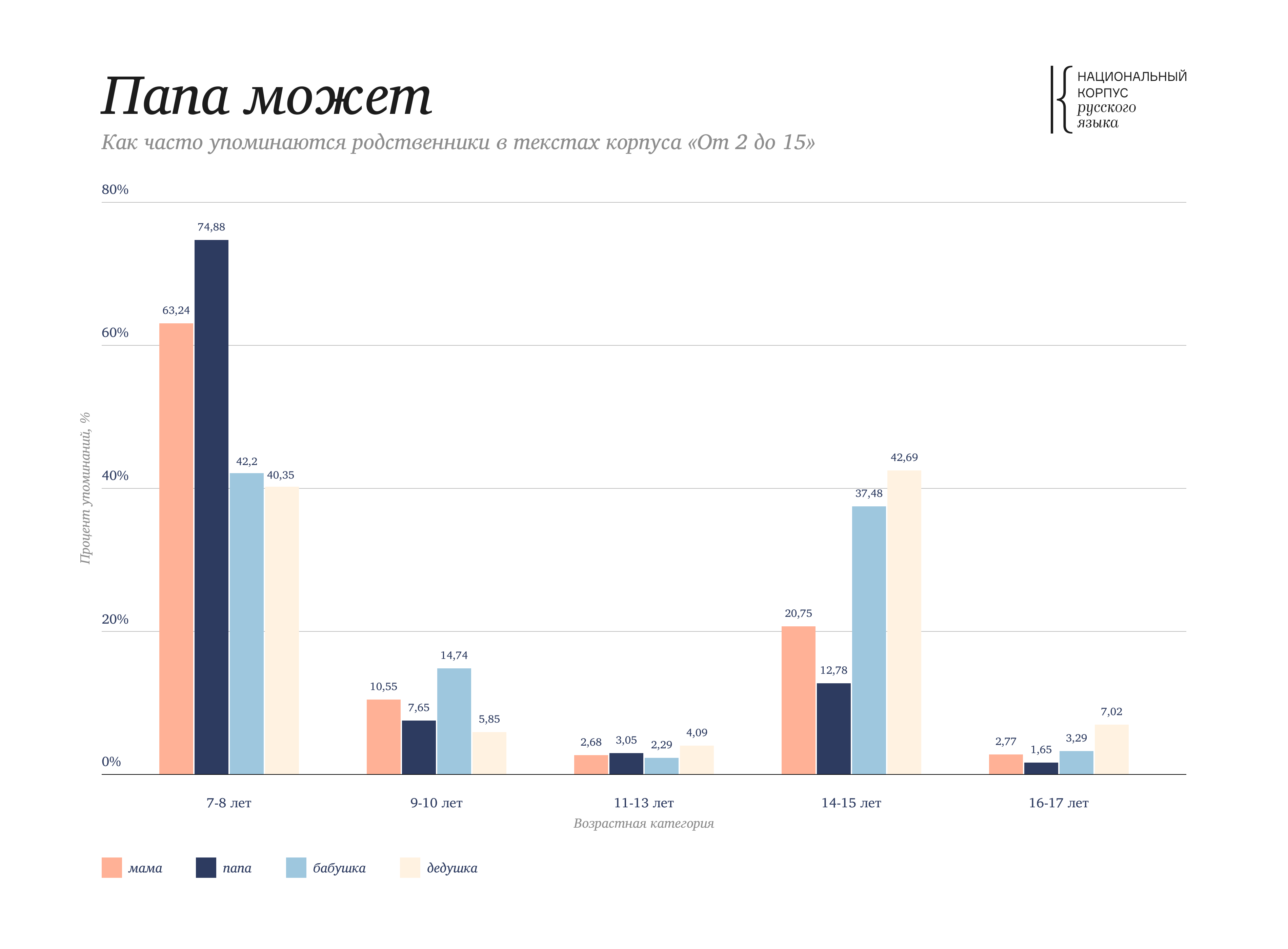
In the Word at a Glance you can see that the words мама 'mom' and папа 'dad' are used much more often in texts for the children of 7-8 years old, and the words бабушка 'grandma' and дедушка 'grandpa' has an equal frequency rating for both the children of 7-8 years and for teenagers of 14-15 years.
The bar next to the fragment indicating the age of readers who should understand these fragments is now clickable. When you click, you will see the calculated classical readability indices: Flesch-Kincaid Index, Coleman-Liau Index, Automatic Readability Index, Simple Measure of Gobbledygook, Dale-Chull readability formula.
In anticipation of the 20th anniversary of the National Corpus, we have significantly updated the publications page on our website. The list of publications about the Corpus has been expanded: the number of publications has increased by about 5 times! The section now includes both academic articles and other types of publications such as interviews, instructions, and social media posts.
The page of publications about the Corpus has advanced functionality: now you can find a publication about the Russian National Corpus in the search bar or using the filters on the right.
By default, the most popular filters are shown to the user. To see all available filters on the publications page, click "Show all". Combining multiple filters narrows the search and allows publications to be selected using multiple criteria.
Some publications can be downloaded by clicking on the icon to the right of the title. Other publications open in a separate window. You can share the list of selected publications by clicking on the "Copy link" button.

Two new parallel corpora are available. The Japanese-Russian language pair has more than 400 thousand tokens and includes fiction texts and news translated from Japanese. The Khakas-Russian texts prepared for the RNC on the basis of the Electronic Corpus of the Khakas Language feature more than 1 million tokens and cover folklore (including 19th century records), written fiction, and journalism.
The existing parallel corpora have also been expanded. The Portuguese pair (now 1.6 million tokens) and the Czech pair (4.3 million tokens) have grown the most.
New widgets are now available at the Word at a glance in the National Media, Educational and Russian classics corpora.
Sketches, Word frequency and Similar words have appeared in the National Media and the Russian classics corpora. Since Word at a glance is built on the base of the corpus texts, sketches and similar words for the same word are different in different corpora. For example, in the texts of the National media corpora, шутка ('joke') is most often злой ('evil') and первоапрельский ('April Fools’') and in the works of Russian classics — it is колкий ('sharp') and забавный ('funny').
The Statistics widget in all three corpora has been updated. Follow the link to find out in which type of texts of Russian classics the word anecdote is more often used.
In March, the Syntactic сorpus was significantly upgraded. New information and search fields appeared within SynTagRus. Starting from Word 2, one may specify coreference and temporal relation. In the Additional Features field one can now search for elided words, i.e. words that are omitted in a sentence but are present in its syntactic structure.
Searching by microsyntactic annotation allows finding stable expressions of different types. For example, by selecting the constructions vsë ravno 1 (~'all the same'), vsë ravno 2 and vsë ravno 3, the user can see the specific semantic features of this polysemous idiom ('in any way', 'indifferently' and 'equivalently', respectively) and the specific features of its usage (for example, vsë ravno 2 and 3 act as predicate, while vsë ravno 1 does not).
Sorting the search results by text date, author's date of birth, annotation date and random sorting is now available. By default, the results are sorted by the annotation date of the texts.
Hints appeared in the menus of syntactic relations, lexical functions and morphological features. Clicking on the (?) button in the neighboring window will open the corresponding description in the User's Guide.
The Russian Classics corpus has implemented automatic annotation using neural network mechanisms. It now offers the same search and statistical tools as the Main, Media and other "advanced" corpora: frequency, n-grams, statistics, sketches in the Word at a glance function, search by syntactic relations, comparison of subcorpora by frequency dictionaries, etc. The Russian Classics is the only one of the RNC corpora where both verse and written prose are represented, and it is now possible to select poetic or prosaic texts separately. With all this we can compare what the Russian classics wrote about. For example, we can problematize alleged "human-centeredness" of Russian classical literature (see picture), and also notice that poets (see Zhukovsky, Baratynsky, or Lermontov mentioned duša 'soul' much more often than authors of prose (see Radishchev, Gogol, or Turgenev).

The Syntactic Corpus now offers the possibility to select a subcorpus by basic parameters, such as author, text title, date of creation and author's year of birth, as well as by genres and text types and by markup date.
Follow our news on the website and social networks, in March we will continue to improve the Syntactic Corpus!


In February, we significantly improved the National media corpus.
It was updated with new texts counting 49,6 million tokens. These are printed media from the 1990s ("Nezavisimaya Gazeta", including weekly supplements, "Moskovsky Komsomolets", and "St. Petersburg Vedomosti").
In all the texts of the corpus, grammatical homonymy has been automatically resolved and annotation of syntactic relations (starting from the second token upon clicking "add condition") has been completed. Thus all the latest functions that are already available in the Main and Regional media corpora, such as searching by syntactic relations and properties, collocation search, frequency dictionary, frequency of query results, are also searchable within the National media corpus, the largest of the three.
The RNC Media corpus is now the world's largest Russian online corpus with the ability to search by syntactic relations!
In the form of the subcorpus, it is now possible to select texts by topic and type. For annotation of these fields RuRoBERTa model is used, further trained on the Regional Corpus data. Fields in the form of subcorpus and text information with values generated by NeuroRNC, are marked with a special icon. Errors are possible with automatic annotation. There is a "Report an error" button in the text information pop-up window. Please inform us of any inaccuracies or errors in the definition of topics and types.

The Russian Classics corpus was expanded by more than 1 million tokens. Complete works by Alexander Radishchev and Ivan Krylov were added, as well as some texts by authors already represented in the corpus that had been omitted in the previous release of the corpus. The function of diachronic graphs is available, queries can be compared, and subcorpus can be customized by both genre and date. The search results can now be sorted by date of creation and by author and genre.
The Сorpus portrait now features diachronic statistics for the Main and Regional corpora. Distribution of the corpus size and metatextual parameters by creation date is represented on a graph. Within the Regional corpus, distribution of texts by countries and regions is also available diachronically.
To see diachronical graphs, click the (i) button in the corpus header, select Statistics and navigate to Diachronic statistics.
The user may specify smoothing, date range, and distribution (axis step), the choice is applied at once to all the graphs on the page.
