RNC News
Since December 2023, two registration and authorization options are available — directly on the website and via Yandex ID.
A small fraction of users have registered on the RNC via ORCID.org. Due to the changes in the legislation of the Russian Federation that came into effect, this option of authorization is no longer available. We apologize for any inconvenience caused to users who previously registered via ORCID.org. Please register again to access the advanced functionality of the RNC.
The Word at a glance service is available not only with the Main corpus, but in general with all the corpora featuring the new interface.
Now getting into the Word at a glance service has become easier. In the header of each corpus there is a button navigating to the Word at a glance service within this particular corpus.
Don't forget that there are other ways to access Word at a glance service:
- from the homepage of the RNC you can go to the Word at a Glance within the Main corpus, find a word, and then switch to any other corpus and see this service with the same word within a new corpus.
- The link to the Word at a glance service is available also in the search results, in the word-by-word annotation pop-up window.
- The Word at a glance service can be accessed via direct links. Meet this function for the word слово within the Old East Slavic corpus and within the Parallel Russian-Chinese corpus.

The Multimedia corpus has been expanded to 5.8 million words. The corpus features new collections of public and non-public speech recorded in different regions, as well as collections of TV publicity and theatrical speech.
Graphs are one of the most sought-after tools for analyzing search results in a corpus. It is important that the conclusions you draw from the graphs take into account the relevant information. For this purpose, we have updated the graphs with several auxiliary tools.
Using the "windows" displaying dates and frequencies in the graphs, you can zoom in or out on certain parts of the graph, and move around values on the axes. This is useful when you want to look at a narrower time or frequency range within a larger amount of data.
In the Main, Media, and Educational corpora, below the graphs there are "warming stripes" showing the number of texts in which examples are found. The intensity of the color of the scale draws users' attention to the fact that a change in the shape of the graph does not necessarily mean a change in the number of uses of the word, but that it may be due to a small number of texts found. In such cases, you may plot a graph without smoothing to verify your findings.
A graph can now be downloaded as a high resolution picture.


As a reminder, two weeks ago we updated the Educational corpus and added the state-of-the-art tools to the corpus.
We had so many updates that they didn't fit in the announcements of the previous release, so we keep you in touch about the updates.
Meet the updated RNC School page. Here you will find useful information on how to use the Russian National Corpus at Russian and Literature school lessons and for independent work at school and at home.
We have updated the section with materials for teachers, as well as a collection of exercises, including complex ("olympiad") assignments.
The Word at a Glance service within the Educational Corpus has been supplemented with the Morphemic structure widget. In other RNC corpora, morphemic structuring is based on a morphemic analysis dictionary specially developed for the corpus. Such structuring is intended for researchers and may not coincide with those accepted at school.
A special version of the widget is implemented in the Educational Corpus. Here the morphemic structure of a word is determined in accordance with the practice of morphemic analysis at secondary school and is based on Alexander Tikhonov's Morpheme Orthographic Dictionary (2002) that contains about 100 thousand lexemes. For words not included in the dictionary, the morphemic structure is not determined. For more details on the morphemic annotation within the RNC, see description.

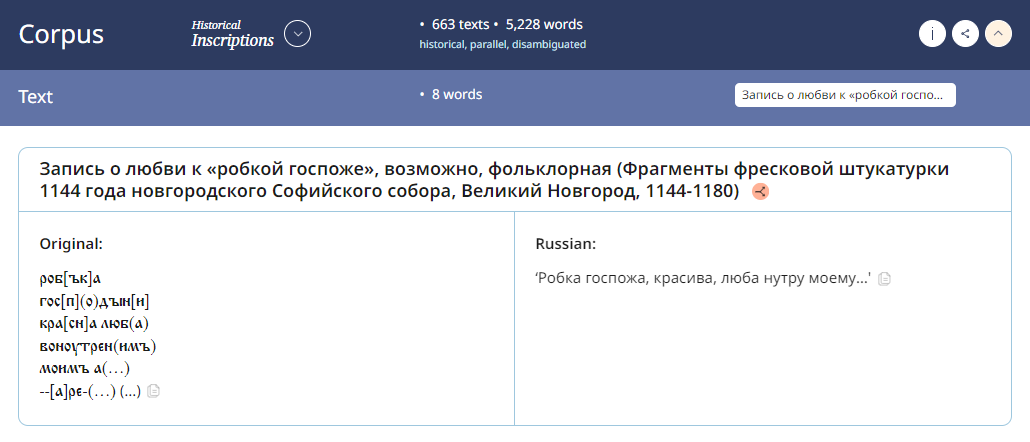
The Russian National corpus now has a brand new historical subcorpus, the one of East Slavic Epigraphy (Inscriptions).
This corpus includes 663 morphologically annotated, mainly brief texts dating back to the 11th-15th centuries from the territories of modern Ukraine, Russia and Belarus, as well as those found outside Eastern Europe, as in Germany, France, or Turkey. These are inscriptions on the walls of churches, on stones, and on objects found during excavations or stored for many centuries. This is a valuable source both on the history of everyday Old East Slavic speech and on the existence of ecclesiastical, literary and folklore texts. From each text users may navigate to the epigraphica.ru database, where more details about the text and photographs are included.
The Old East Slavic corpus has been updated. Its size exceeded 800 thousand tokens. The corpus now features new texts. These are several dozens of official texts dating back to 12th-14th centuries: princely laws, charters from Novgorod, Polotsk, Ukraine and the Grand Duchy of Lithuania. For the first time the early corpus includes the ancestors of such modern Russian words as блистать, больница, великолепие, доход, дружить, наслаждение, околица, простоволосый, ящерица.
The Russian and English-Russian parallel MultiPARCs have navigated to the new interface. Word at a glance and Get overview features are now available.
To select your own subcorpora and use our statistical services, you need metatextual annotation. RNC already features more than 6 million texts and is constantly growing. It is becoming less and less feasible to mark up such a large amount of data manually, so we are developing neural annotation services (NeuroRNC). Today we present new results in the field.
Keywords in the texts of the Regional Media corpus are annotated automatically using the adapted rutermextract model. One keyword can consist of a single token (праздник, переломы) or a two-word combination (таяние снега). The single-token query (сообщество) yields both exact matches and two-word combinations with this word (католическое сообщество).
In the Social Networks corpus, genres are automatically labeled for the main corpus texts. The RuRoBERTa model, fine-tuned on the corpus texts, is used for annotation. One or more genres can be selected from a list, e.g., recommendations and advice.
In the text information, the fields filled in by NeuroRNC are marked with a special icon. In the same pop-up window there is a "Report a bug" button. Please let us know about any inaccuracies or errors in the definition of keywords and genres.

The Multimedia corpus has been switched to a new interface. Now the corpus search is redesigned, the "Word at a Glance" service is available.
A special feature of the corpus is the multimedia search functionality. Three search queries may be specified simultaneously: for words, gestures and speech acts. You will find clips where both video/audio and text match these queries: for example, those with the preposition за in speech and тост (toast) as gesture.
Please note that by default the form hides some of the conditions for words, gestures and speech act. One can add these conditions by clicking the “Add Conditions” button.
For example, to find clips in which somebody moves their head in a certain way, you need to add two conditions in the Gestures section: for the Main organ and for the Gesture direction. Then you may specify, respectively, голова (head) and из стороны в сторону (side to side) as features. To find clips where people whisper, please add a condition for the Manner of speech to the search form and select the value шепот (whisper).
Additionally, you can set conditions describing the vocalic and orthoepic structure of words.

The annual update of the Birchbark letters corpus is released. Fifteen medieval letters found in Veliky Novgorod and Staraia Russa last year - and yet two more awaiting academic publication since 2021 - are now simultaneously available in the RNC and in the gramoty.ru database. The work on the corpus of birchbark letters was supported by a grant from the Russian Science Foundation (Project 19-18-00352 "Vernacular writing of Old Rus' of the 11-15 centuries (birchbark letters and epigraphy): new sources and research methods"). An illustrated story about the findings of the last year can be read on the Arzamas website.
We have updated the Educational Corpus with over 1,000 new texts. It now contains all the major works from the school curriculum, including those recommended for extracurricular reading.
But that's not all. For morphological annotation of all texts we have applied neural network models. The automatic annotation has resolved grammatical homonymy, allowing us to add modern tools for analyzing words and texts to the Educational Corpus.
The Word at a Glance function shows collocations, similar words, frequency of use, paradigms and history of use, as well as examples from corpus texts. You can use the Query comparison to compare the frequency of use of words and phrases.
You can also analyze texts. For this purpose, there is the Corpus portrait section, which provides information about the history of creation and composition of the corpus, as well as statistics and frequency vocabulary. With the Subcorpus portrait section, one can analyze the features of selected texts and compare them with the rest of the corpus.
With the new tools, it is possible to compose more diverse assignments for students. Students can also use them for independent research, for example, for writing an essay. For those teachers and students who are ready to conduct more complex research, we have added new types of search results output (Statistics, Frequency, N-grams) and a new type of search – Collocation Search.
In the new version of the Word at a Glance function within the Main Corpus, the "families" of cognate words have been supplemented by the NeuroRNC neural network model. For example, for the word актер, all the cognates except for актриса and киноактриса are found out by NeuroRNC. Also, if NeuroRNC finds at least 5 words with the same root, we add a new family of cognate words to the Word at a Glance function, even if the word you are looking for was not in the morphemic parsing dictionary. A very impressive word portrait was obtained for the word эстет using only neural networks algorithms.
In order to help our users interpret the results of search queries, we have matched each tag of semantic markup with names in Russian and English. Now in the pop-up window in the search results and in the Word at a glance function you can see supernatural beings, substances and materials or positive evaluation instead of convenience tags such as t:hum:supernat, t:stuff, or ev:posit.
