RNC News
This year, the RNC actively collaborated with Total Dictation, an annual educational event that unites people who speak Russian and strive to write correctly.
On the day of the dictation, Vladimir Plungian shared his thoughts on why the RNC is necessary for both linguists and non-linguists, how it changes, and which years were the most productive in the history of the Corpus. Watch the recording of the conversation; it's informative and exciting.
The Old East Slavic corpus features fourteen new texts with a total size of 120,000 tokens, including such famous works of Old East Slavic literature as "Sermon on Law and Grace", "Daniel Zatochnik's Prayer", "Kyivan Cave Patericon", the Slavic translation of "The Life of Basil the Younger". The corpus now includes different textual versions of different texts such as "Tale of Bygone Years", "Life of Theodosius", or the cycle on Boris and Gleb. More than 1,000 Old East Slavic lexemes have been added to the corpus, including the ancestors of such Russian words as выискивать, известие, избранник, пчелка, невежественный, стремглав, умышлять.
We continue to update the «Word at a Glance» feature. Now you can see the "Similar Words" cloud and Word frequency in the Middle Russian corpus and the "Similar Words" cloud in the Birchbark letter corpus.

Beta testing of the «Similar words» cloud within the «Word at a Glance» option continues. Thanks to your feedback we were able to improve the vector model that looks for similar words. We are waiting for new feedback on the «Similar words» clouds in the Main and Regional corpora and for your reaction on the «Similar words» cloud in the Middle Russian corpus. You can leave feedback by clicking the «Rate» button next to the feature.
The five examples in the «Word at a Glance» feature are now selected at random, which means that with each new viewing of the Word at a Glance feature there is a chance to see something new.
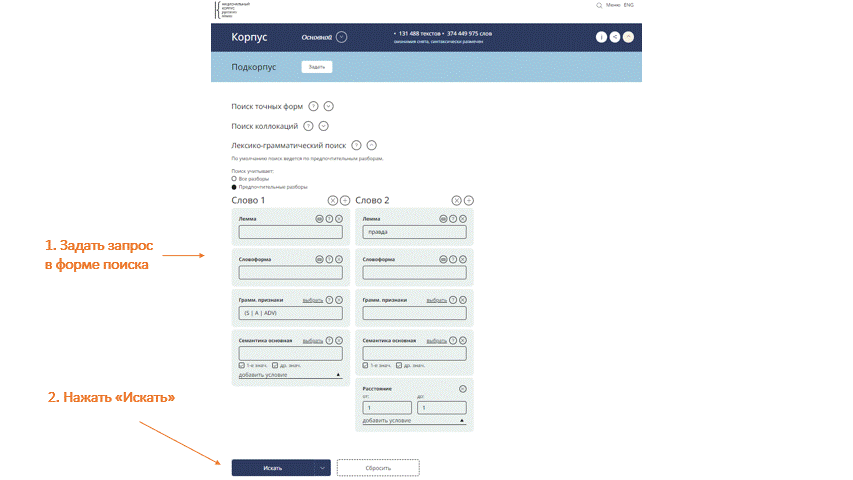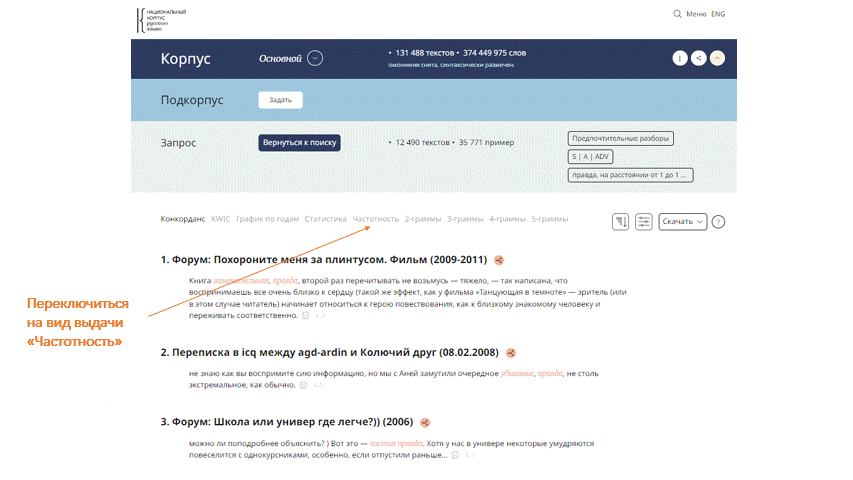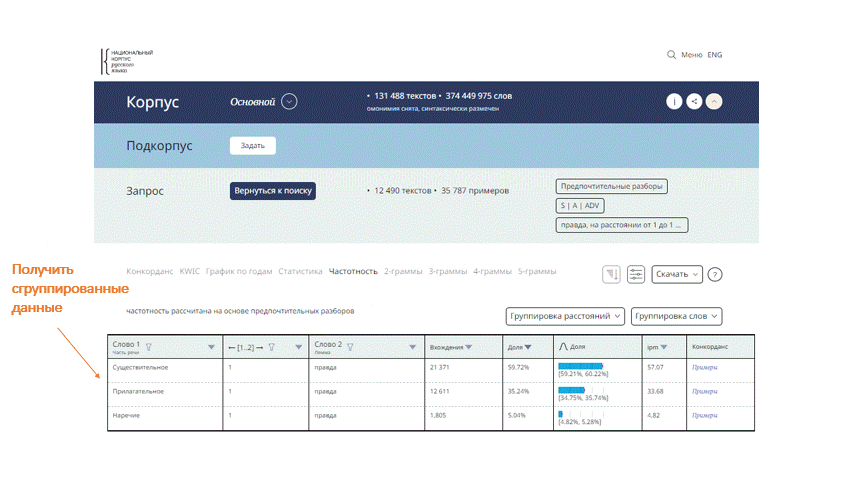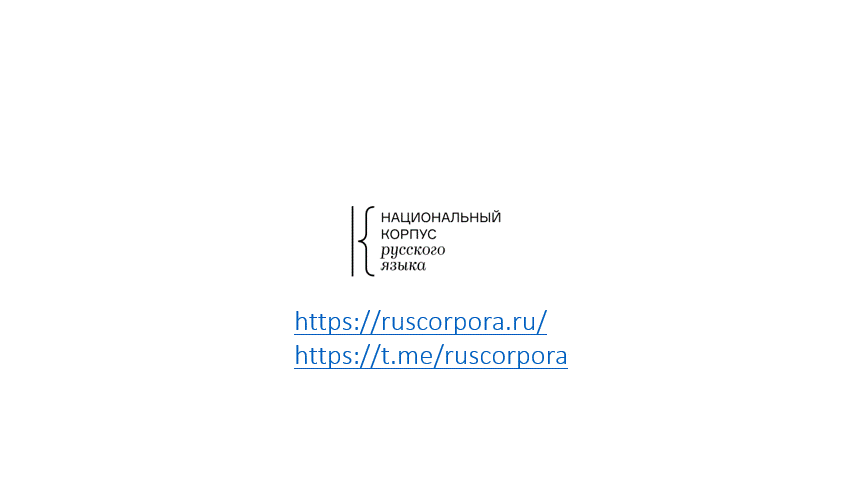
Word Portrait has been updated:
- Sketches and "Similar Words" are now available not only in the Main corpus, but also in the Regional corpus as well
- The information about frequency of words has been added
- The most frequently occurring part of speech for the target word is now displayed in the portrait (e.g. noun is displayed first for query печь, and verb is displayed first for query стать)
A new corpus of Social networks appeared within the RNC. It features more than 160 million word uses since 2007. All texts are taken from open sources: VK, Telegram, Livejournal, Liveinternet, Blogspot. “Social networks" are defined as widely as possible, including blog posts and messengers. Language in social networks is the most dynamic and free from regulatory restrictions. It reflects changes in vocabulary (including slang), semantic evolution, developments in grammar, and typical mistakes.
The Dialect corpus interface has been substantially updated, the corpus is connected to the “Overview” feature. Metatext markup has been edited (in particular, the selection of geographical locations has been improved). Within the dialect corpus, running multimedia clips can be performed directly in the output interface.
We launch a β-version of the search for user manuals, corpus descriptions, announcements, and other materials available on the RNC site. The current version of the Site Search has some limitations, please read the description.
The Word Portrait functionality in the main corpus has been improved and expanded:
The new Sketches section allows the user to understand how a word interacts with other words in the language. This interaction is defined through the compatibility (collocations) with words of different parts of speech. This takes into account the various syntactic functions of a word in a sentence, which cover the main domains where a given word “works” in the language. One can search what respect is like in Russian and what one may make with it. Another query explores the compatibility of the word bring in Russian. Whereas one usually brings some abstract notions (as far as the texts show us), the most frequent subjects of bringing are quite material.
For nouns, adjectives, verbs, and adverbs, up to 10 of the most closely related words in each sketch are displayed. For other parts of speech, the sketches are not shown.
The Similar Words section now uses its own model to search for semantic associates, trained on actual texts from the main corpus of the RNC. The new model allowed us to reduce the number of errors. But due to the fact that the selection of similar words is fully automatic, errors (e.g. non-existent word forms) can still occur.
To see all the information on a given word, you can now use the Word at a glance functionality. As of today, the Word Portrait includes:
- grammatical and semantic properties of the word
- Similar words (β, only in the main corpus)
- word usage examples in the corpus
- distribution of examples by year and by type of text
For quick access to the Word Portrait and other corpus features as well as to the User's Guide you can now use buttons on the main page of ruscorpora.ru.
The output view Frequency has been improved:
- The "Contexts" column has been added
- Grouping of results can be either disabled or applied for some words only. Users can retrieve combination of words with any distance between them (within the distance specified in the original query). Some of the words can be grouped by lemma/word form/grammatical features, and the remainder is retrieved without grouping. For example, for the query красивый ('beautiful’) + any noun one can get the frequency distribution of all nouns found in the search results and the overall frequency for the combination with any noun as well
- The size of the downloaded table with "raw" data can reach 5000 lines
The frequency dictionary of a subcorpus as compared to the entire corpus can be sorted by differences of lemma ranks. The lemmas that are found only in the subcorpus top 500 frequent items are given first, followed by those with the highest gain in frequency rank with regard to the statistical population. For example, the frequency dictionary of texts written by women can be sorted in such a way that it starts with the characteristic lemmas like девочка (‘girl’), стараться ('try’), проблема (‘problem’), искусство (‘art') etc.
A new corpus "Russian classics" is available. It includes poetic, prosaic, journalistic and epistolary works from representative academic editions by Russian classical writers of the 19th - early 20th centuries: Pushkin, Baratynsky, Gogol, Tolstoy, Turgenev, Chekhov and others. A significant part of these texts are also included into the Main or Poetic corpus. Currently the corpus is in beta-version ("Russian classics β"). New authors and works are to be added later. The size of the corpus is more than 17.5 million tokens.
The interface of the Birchbark letter corpus has been substantially updated, and the corpus is connected to the Overview feature. Early Old East Slavic lemmas are available for search (not only слати, but also сълати ‘send’). An important innovation is that the original and translated texts are now shown in two columns, and a translation (Russian or any of the two English variants) can be chosen to be displayed.
The functionality of the main corpus has been significantly upgraded. Now it features lexical and grammatical annotation with automatic homonymy resolution and automatic syntactic annotation. Within the main corpus grammatical homonyms are disambiguated. It is also searchable by syntactic parameters such as types of compound sentences, predicative phrases (clauses), complements, copulas, and many others. With this new annotation, all the new functions that appeared earlier in the corpus of regional media are available in the main corpus: Searching for collocations, Frequency dictionary, Search results types. Frequency.
In addition, the main and newspaper corpora now are searchable for lemmas and word forms using regular expressions (β-version). They feature corpus and subcorpus statistics: overall size in texts and words, a geographical map (for the Regional media corpus only) and charts of metatextual attributes. These functions allow users to compare a given subcorpus with the bulk of the corpus, including the visualization.
The interface of the Church Slavonic corpus has been substantially updated, and the corpus is connected to the Overview feature.
The multimedia corpus counts 5.7 million tokens.
The parallel corpus counts 168 million tokens. Now it features four new language pairs with Russian, namely two larger South Slavic subcorpora, Serbian and Slovene, as well as two smaller pilot corpora of Korean and Hindi, both coming with transliteration and dictionary support. The Korean and Hindi tiers include aligned poetical texts, a new feature within the parallel corpus. The Czech and Spanish language pairs are also updated.
The interface of the Middle Russian corpus has been significantly updated; the corpus is connected to the Overview feature.
The Regional corpus has a new type of output: Frequency. With it, the statistical distribution of search results by lemmas, word forms and a set of grammatical features can be analyzed. The frequency is calculated based on texts with automatically removed homonymy over a random subsample of 1 million search results. Users can control the confidence level to compare frequency confidence intervals.
The Dialect corpus has been updated and now contains 604 thousand tokens.
The SynTagRus has increased by 30 thousand tokens.
The corpus and subcorpus frequency dictionaries now feature 500 top lemmas rather than 100.
The RNC sums up the results of 2022. There have been many changes this year: the size of the whole Corpus reached 1.5 billion tokens, two new subcorpora were inaugurated (Panchronic and "From 2 to 15"), the corpus of birchbark letters went parallel, the regional corpus is now disambiguated and features collocations and frequency tools. The old version of the RNC is now closed. The RNC is also migrating to a new interface. All the changes are shown in more detail in the picture.
The Birchbark letter corpus is updated with the texts of archaeological findings from the year 2021, published in 2022. These are the new documents from Veliky Novgorod and Staraya Russa, as well as the very first birchbark letter discovered in Pereyaslavl Ryazansky (modern-day Ryazan).
A new corpus "From 2 to 15" featuring 75 original and translated texts in prose, read by modern children and teenagers, is inaugurated within the RNC. The main distinguishing feature of the new corpus is the automatic annotation of text fragments according to the age of readers that should be able to understand these fragments. The model is being tested, so mistakes can still appear in this annotation.
The Educational corpus interface has been substantially updated, the corpus is now available with the Get overview feature, and the description of the corpus has been updated.
A section "Corpus-based exercises" has been developed, which presents exercises based on the Educational Corpus and other corpora within the RNC. The exercises belong to different sections of the school Russian course and are designed for independent work in the classroom and at home, as well as for testing. We plan to develop and update the section with new exercises. The corpus users can also participate in the process. We invite teachers and professors to use the corpus to compose their own unique assignments and exercises. Feel free to send us some of your best ideas on info@ruscorpora.ru. We will publish them in the exercises section.
Each corpus within the RNC has its own Corpus Portrait. The Corpus Portrait functionality is designed as a tool that allows a RNC user to analyze the characteristics of a given corpus and assess whether the corpus in question is suitable for their research or teaching needs. The corpus portrait at this stage includes:
* a description of the corpus
* frequency dictionary (only in the Regional Media Corpus)
All the RNC corpora have tags on a meta-corpus level, allowing to categorize them by historical period, text type, presence of specific annotation, etc.
If a subcorpus has been customized, users also have access to the respective "Subcorpus Portrait" function. With this tool, by clicking the (i) link in the header of the corpus, one can see the list of selected texts and compare the statistical characteristics of the corpus to the respective parameters of the customized subcorpus. For example, one can compare the frequency dictionary of the regional corpus to those of subcorpora selected within it.
In 2023, more statistics will appear in the Corpus and Subcorpus Portraits.