The RNC can show the search results in several formats. All corpora support two types: Concordance and KWIC; other formats are optional.
Types of results presentation
Concordance
In the Concordance mode, the examples are grouped according to the texts in which they were found.

In parallel corpora, examples are displayed in two columns. On the left you will see a fragment of the text in the original language, and on the right you can choose one of the translations.
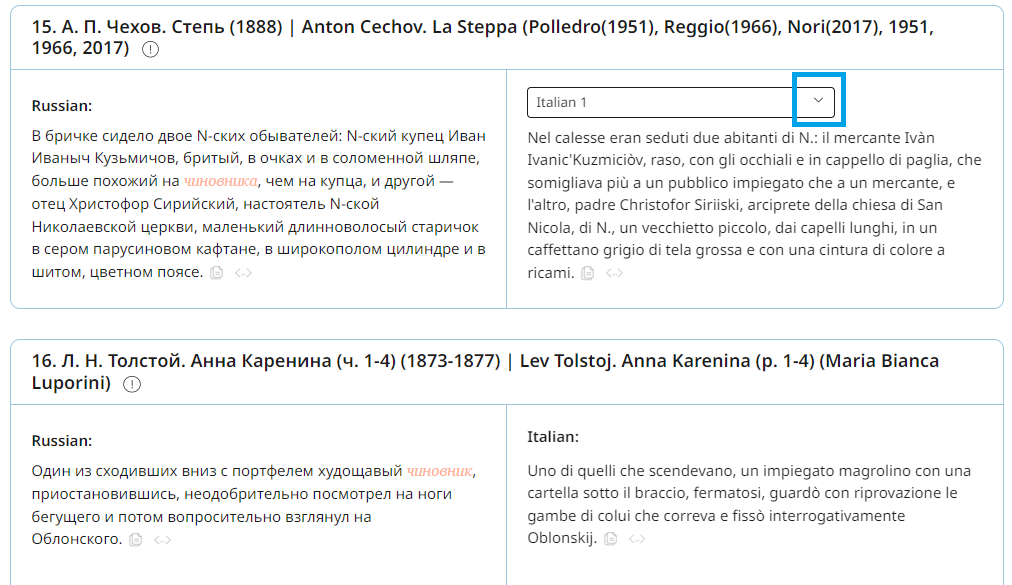
In dialect and multimedia corpora, examples are accompanied by parallel video or audio fragments. The gesture table is displayed if the gestures are annotated.
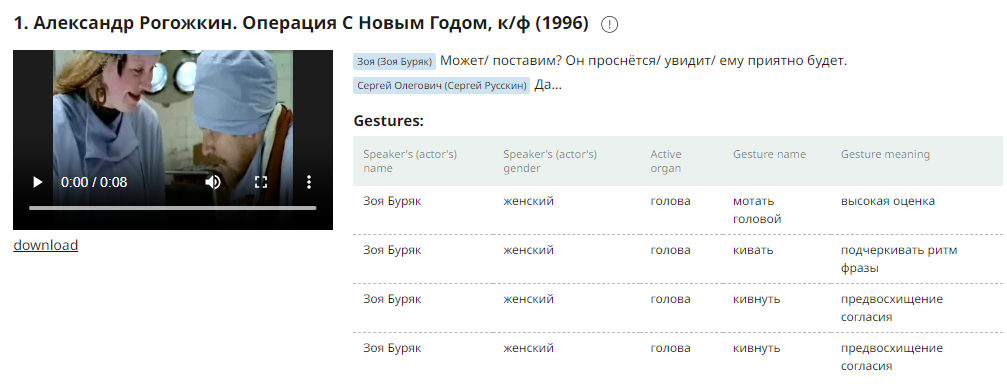
Use Settings if you need to customize how many documents are shown on one page and how many examples are shown in each document.
See Search results analysis to learn how to find more information on the query results.
KWIC
In the KWIC (Key Word in Context) mode, the central word is highlighted and surrounded by its left and right context.

In the KWIC mode additional sorting settings according to the left or right context are available.
You can select the central word switching between words in the Query bar. The current central word is highlighted in orange and marked by a check mark.

See Search results analysis to learn how to find more information on the query results.
Graph
For several corpora, an additional mode is available in which the distribution of the search results by date (instances per million, ipm) is shown. In the Regional Media corpus graphs are now plotted using days, months or years as units of measurement, in other corpora - only years. You can either use the default graph or specify a time period or smoothing.
In some corpora, beneath the graph, warming stripes are visible, illustrating the number of texts in which examples were found in the given subcorpus.
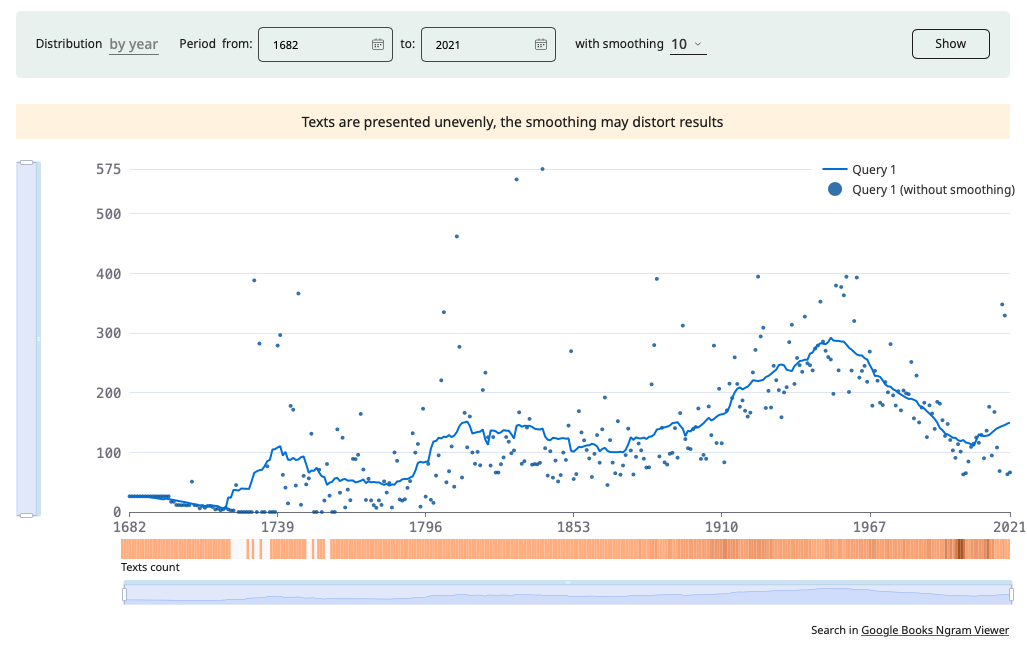
Click Download to save the graph as a picture file.
For more information about graph analysis, see the article Chronological distribution of search results.
Statistics
In the Statistics mode you are shown the distribution of the texts that were found according to the values of several meta attributes (e.g. Authors, Text types, Genres).
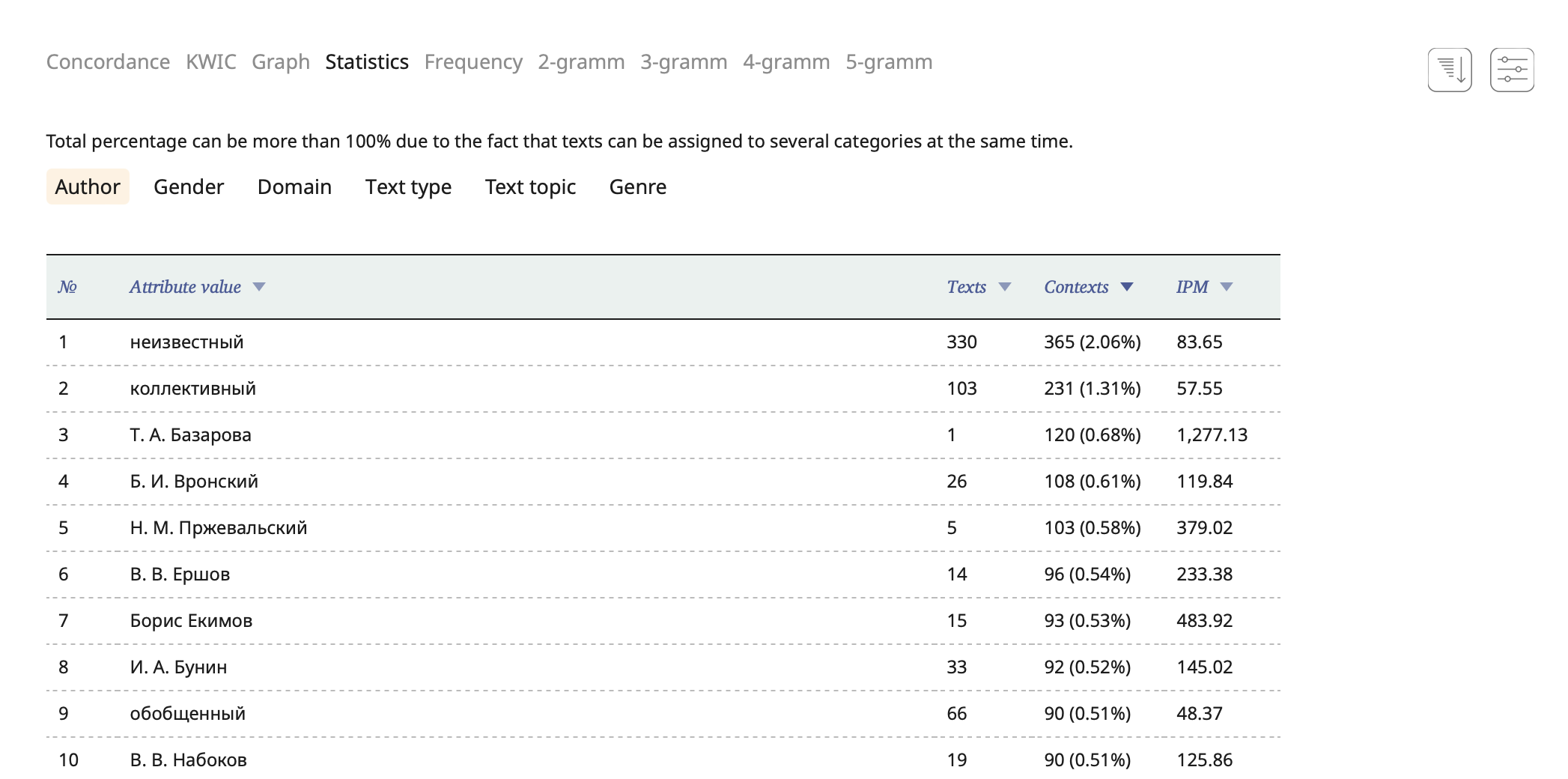
In each corpus, the Statistics mode shows a different set of tables, determined by the attributes that characterize the corpus texts most precisely.
By default, the table is sorted by contexts. To change the sorting criterion, click on the column name.
Currently, the Statistics mode is available for the Main, Educational and some other corpora. Later it will be added to more corpora.
Frequency
In the Frequency mode the frequency distribution of the search results is shown. In the frequency table, you can see which word forms, lemmas, or sets of grammatical features most often match the specified query conditions in the search results.
Such output can be especially useful if the query contains lemmas and tags for several words with specified distances between them. For example, you can find combinations of an adjective and a noun that are at a distance of -1 to 1 from each other, which means that both orders are possible. The distribution of the 100 most common combinations will be shown in the table.
Currently, the Frequency page is shown in the Main, Educational, Media and some other corpora. Later on, this feature will be added to more corpora.
N-grams
N-grams are sequencies of n words, including the words in the query. For example, for a two-word query, you can be shown bigrams (sequencies of the two words of the query), 3-grams (sequencies of 3 words including the two words of the query), 4-grams (sequencies of 4 words including the two words of the query), etc.

The n-grams are sorted according to ipm in descending order, so that the most frequent sequencies are shown at the top. The n-grams table shows the number of the documents in which it was found, the number of occurencies, the ipm frequency for the selected corpus and the n-gram itself, with a hyperlink to the examples in the corpus.
Currenly n-grams are only given for word forms. N-grams for lemmas will be available in the Frequencies mode, currently under construction.
N-grams are now available for the Main, Educational, Media and some other corpora. Later, it will be added for more corpora.
Default view of the results
By default, the search results are presented in the Concordance mode, and one can switch to another available type of search results using the Search results presentations menu.

Experienced users can choose their favourite search results presentation in the menu on the Search button. The selected search results type will be stored and later it will be used by default.
Updated on 30.09.2025